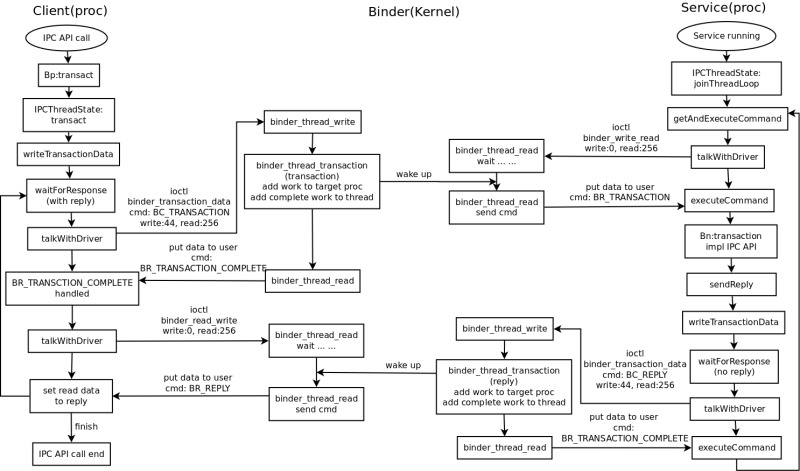
通信就要搞一些协议,binder 的比较简单,但是也有一个基本的模型,这里以最基本的一次 IPC 调用来说明一下。然后涉及的代码主要在(这里不列 java 层的代码了,java 层的代码前面原理篇分析过了,主要是挂马甲调用 native 的方法的):
1
2
3
4
5
6
7
8
9
frameworks/native/include/binder
frameworks/native/libs/binder
kernel/drivers/staging/android/binder.h
kernel/drivers/staging/android/binder.c
流程
先上张图先,图我尽量简化,只画了 IPC 调用相关的东西(是 4.4 来分析的,之前的版本有点点小区别):
1、服务端等待请求
首先看图上右边的服务(service)部分。service 进程运行起来,然后通过调用 IPCThreadState 的 joinThreadLoop 在本线程中开始等待客户端请求的到来。这里有2个问题:第一个,system service 必须向 service manager 注册自己;第二个,服务端的多线程支持问题。这里都后面再说。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
void IPCThreadState::joinThreadPool(bool isMain)
{
LOG_THREADPOOL("**** THREAD %p (PID %d) IS JOINING THE THREAD POOL\n" , (void *)pthread_self(), getpid());
mOut.writeInt32(isMain ? BC_ENTER_LOOPER : BC_REGISTER_LOOPER);
set_sched_policy(mMyThreadId, SP_FOREGROUND);
status_t result;
do {
processPendingDerefs();
result = getAndExecuteCommand();
if (result < NO_ERROR && result != TIMED_OUT && result != -ECONNREFUSED && result != -EBADF) {
ALOGE("getAndExecuteCommand(fd=%d) returned unexpected error %d, aborting" ,
mProcess->mDriverFD, result);
abort ();
}
if (result == TIMED_OUT && !isMain) {
break ;
}
} while (result != -ECONNREFUSED && result != -EBADF);
LOG_THREADPOOL("**** THREAD %p (PID %d) IS LEAVING THE THREAD POOL err=%p\n" ,
(void *)pthread_self(), getpid(), (void *)result);
mOut.writeInt32(BC_EXIT_LOOPER);
talkWithDriver(false );
}
这里看得出,这个函数是个循环(等待——处理——等待 … … 一般服务器的模型都是这样),参数 isMain 表示这个 service thread 是不是主线程,这个东西后面再说。循环里面主要是调用 getAndExecuteCommand 来处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
status_t IPCThreadState::getAndExecuteCommand()
{
status_t result;
int32_t cmd;
result = talkWithDriver();
if (result >= NO_ERROR) {
size_t IN = mIn.dataAvail();
if (IN < sizeof (int32_t)) return result;
cmd = mIn.readInt32();
IF_LOG_COMMANDS() {
alog << "Processing top-level Command: "
<< getReturnString(cmd) << endl;
}
result = executeCommand(cmd);
set_sched_policy(mMyThreadId, SP_FOREGROUND);
}
return result;
}
getAndExecuteCommand 这个名字就可以看得出这个函数主要干2个事情,一个取请求数据、一个就是处理请求数据:正好又分了2个函数: talkWithDriver 和 executeCommand(下面那个好像是设置线程优先级,先不理这些东西先)。
先来看下 talkWithDriver:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
if (mProcess->mDriverFD <= 0 ) {
return -EBADF;
}
binder_write_read bwr;
const bool needRead = mIn.dataPosition() >= mIn.dataSize();
const size_t outAvail = (!doReceive || needRead) ? mOut.dataSize() : 0 ;
bwr.write_size = outAvail;
bwr.write_buffer = (long unsigned int )mOut.data();
if (doReceive && needRead) {
bwr.read_size = mIn.dataCapacity();
bwr.read_buffer = (long unsigned int )mIn.data();
} else {
bwr.read_size = 0 ;
bwr.read_buffer = 0 ;
}
IF_LOG_COMMANDS() {
TextOutput::Bundle _b(alog);
if (outAvail != 0 ) {
alog << "Sending commands to driver: " << indent;
const void * cmds = (const void *)bwr.write_buffer;
const void * end = ((const uint8_t*)cmds)+bwr.write_size;
alog << HexDump(cmds, bwr.write_size) << endl;
while (cmds < end) cmds = printCommand(alog, cmds);
alog << dedent;
}
alog << "Size of receive buffer: " << bwr.read_size
<< ", needRead: " << needRead << ", doReceive: " << doReceive << endl;
}
if ((bwr.write_size == 0 ) && (bwr.read_size == 0 )) return NO_ERROR;
bwr.write_consumed = 0 ;
bwr.read_consumed = 0 ;
status_t err;
do {
IF_LOG_COMMANDS() {
alog << "About to read/write, write size = " << mOut.dataSize() << endl;
}
#if defined(HAVE_ANDROID_OS)
if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0 )
err = NO_ERROR;
else
err = -errno;
#else
err = INVALID_OPERATION;
#endif
if (mProcess->mDriverFD <= 0 ) {
err = -EBADF;
}
IF_LOG_COMMANDS() {
alog << "Finished read/write, write size = " << mOut.dataSize() << endl;
}
} while (err == -EINTR);
IF_LOG_COMMANDS() {
alog << "Our err: " << (void *)err << ", write consumed: "
<< bwr.write_consumed << " (of " << mOut.dataSize()
<< "), read consumed: " << bwr.read_consumed << endl;
}
if (err >= NO_ERROR) {
if (bwr.write_consumed > 0 ) {
if (bwr.write_consumed < (ssize_t)mOut.dataSize())
mOut.remove(0 , bwr.write_consumed);
else
mOut.setDataSize(0 );
}
if (bwr.read_consumed > 0 ) {
mIn.setDataSize(bwr.read_consumed);
mIn.setDataPosition(0 );
}
IF_LOG_COMMANDS() {
TextOutput::Bundle _b(alog);
alog << "Remaining data size: " << mOut.dataSize() << endl;
alog << "Received commands from driver: " << indent;
const void * cmds = mIn.data();
const void * end = mIn.data() + mIn.dataSize();
alog << HexDump(cmds, mIn.dataSize()) << endl;
while (cmds < end) cmds = printReturnCommand(alog, cmds);
alog << dedent;
}
return NO_ERROR;
}
return err;
}
talkWithDriver 主要是调用 ioctl 去 kernel 的 binder 设备那里读数据。这里的 mDriverFD 是打开 binder 设备的文件描述符。在 ProcessState 的构造函数中会打开 binder 设备(一个进程只会开打一次,然后所有线程共用一个 fd):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
ProcessState::ProcessState()
: mDriverFD(open_driver())
... ...
}
static int open_driver()
{
int fd = open("/dev/binder" , O_RDWR);
if (fd >= 0 ) {
fcntl(fd, F_SETFD, FD_CLOEXEC);
int vers;
status_t result = ioctl(fd, BINDER_VERSION, &vers);
if (result == -1 ) {
ALOGE("Binder ioctl to obtain version failed: %s" , strerror(errno));
close(fd);
fd = -1 ;
}
if (result != 0 || vers != BINDER_CURRENT_PROTOCOL_VERSION) {
ALOGE("Binder driver protocol does not match user space protocol!" );
close(fd);
fd = -1 ;
}
size_t maxThreads = 15 ;
result = ioctl(fd, BINDER_SET_MAX_THREADS, &maxThreads);
if (result == -1 ) {
ALOGE("Binder ioctl to set max threads failed: %s" , strerror(errno));
}
} else {
ALOGW("Opening '/dev/binder' failed: %s\n" , strerror(errno));
}
return fd;
}
回到 talkWithDriver,ioctl 调用的命令是 BINDER_WRITE_READ,参数是 binder_write_read 这个结构。这里每个 IPCThreadState(service 的线程)都还有2个 Parcel 变量:mIn、mOut 分别用于打包发送和接收读取的数据。这些后面再分析 binder 的数据包的时候再说。这里只说前面要向 binder 发命令,就调用 mOut 写命令,要接收数据的话,talkWithDriver 的参数 doRevice 默认是 true,ioctl 能一次性完成读、写操作。
这里第一次 service 写是 0btye,读是 256btye(初始化的 mIn 的 Capacity 是 256,但是 service 开始并没有写入命令)。
然后 ioctl 就到了 kernel 的 binder 驱动里面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2 );
if (ret)
return ret;
mutex_lock(&binder_lock);
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ: {
struct binder_write_read bwr;
if (size != sizeof (struct binder_write_read)) {
ret = -EINVAL;
goto err;
}
if (copy_from_user(&bwr, ubuf, sizeof (bwr))) {
ret = -EFAULT;
goto err;
}
binder_debug(BINDER_DEBUG_READ_WRITE,
"binder: %d:%d write %ld at %08lx, read %ld at %08lx\n" ,
proc->pid, thread->pid, bwr.write_size, bwr.write_buffer,
bwr.read_size, bwr.read_buffer);
if (bwr.write_size > 0 ) {
ret = binder_thread_write(proc, thread, (void __user *)bwr.write_buffer, bwr.write_size, &bwr.write_consumed);
if (ret < 0 ) {
bwr.read_consumed = 0 ;
if (copy_to_user(ubuf, &bwr, sizeof (bwr)))
ret = -EFAULT;
goto err;
}
}
if (bwr.read_size > 0 ) {
ret = binder_thread_read(proc, thread, (void __user *)bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
if (ret < 0 ) {
if (copy_to_user(ubuf, &bwr, sizeof (bwr)))
ret = -EFAULT;
goto err;
}
}
binder_debug(BINDER_DEBUG_READ_WRITE,
"binder: %d:%d wrote %ld of %ld, read return %ld of %ld\n" ,
proc->pid, thread->pid, bwr.write_consumed, bwr.write_size,
bwr.read_consumed, bwr.read_size);
if (copy_to_user(ubuf, &bwr, sizeof (bwr))) {
ret = -EFAULT;
goto err;
}
break ;
}
... ...
}
关于 ioctl 的一些基本知识可以参看下我的这篇文章:[转] unlocked_ioctl 和堵塞(waitqueue)读写函数的实现
这里稍微注意下,ioctl 里面 proc 表示本次调用的进程,thread 表示调用本次调用的线程(这2个主要是记录了进程号 pid 和线程号 tid)。然后第一次 write 的 size 是 0,所以没有处理 binder_thread_write。接下来是取数据: binder_thread_read(这里可以看到出,kernel 是先处理 write 再处理 read 的,原因到后面就知道了)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
void __user *buffer, int size,
signed long *consumed, int non_block)
{
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
int ret = 0 ;
int wait_for_proc_work;
if (*consumed == 0 ) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof (uint32_t);
}
retry:
wait_for_proc_work = thread->transaction_stack == NULL &&
list_empty(&thread->todo);
if (thread->return_error != BR_OK && ptr < end) {
if (thread->return_error2 != BR_OK) {
if (put_user(thread->return_error2, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof (uint32_t);
if (ptr == end)
goto done;
thread->return_error2 = BR_OK;
}
if (put_user(thread->return_error, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof (uint32_t);
thread->return_error = BR_OK;
goto done;
}
thread->looper |= BINDER_LOOPER_STATE_WAITING;
if (wait_for_proc_work)
proc->ready_threads++;
mutex_unlock(&binder_lock);
if (wait_for_proc_work) {
if (!(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED))) {
binder_user_error("binder: %d:%d ERROR: Thread waiting "
"for process work before calling BC_REGISTER_"
"LOOPER or BC_ENTER_LOOPER (state %x)\n" ,
proc->pid, thread->pid, thread->looper);
wait_event_interruptible(binder_user_error_wait,
binder_stop_on_user_error < 2 );
}
binder_set_nice(proc->default_priority);
if (non_block) {
if (!binder_has_proc_work(proc, thread))
ret = -EAGAIN;
} else
ret = wait_event_interruptible_exclusive(proc->wait, binder_has_proc_work(proc, thread));
} else {
if (non_block) {
if (!binder_has_thread_work(thread))
ret = -EAGAIN;
} else
ret = wait_event_interruptible(thread->wait, binder_has_thread_work(thread));
}
mutex_lock(&binder_lock);
if (wait_for_proc_work)
proc->ready_threads--;
thread->looper &= ~BINDER_LOOPER_STATE_WAITING;
if (ret)
return ret;
... ...
}
来看下 binder_thread_read 的前面部分。这里 service 的 wait_for_proc_work 的值为 1,也是 true 的意思。一开始的 thread->transaction_stack 是 NULL 的,这个是表示这个线程的传递堆栈,类似于函数调用堆栈的东西,一开始没传递,这个堆栈肯定是空的(这个也后面再具体分析)。然后一开始 thread->todo 这链表也是空的,这个是表示这个线程上需要完成的工作,这个后面会知道是什么东西。
那根据上面的条件,这里 service 的 ioctl 调用就会跑到这里:
wait_event_interruptible_exclusive(proc->wait, binder_has_proc_work(proc, thread));
wait event 是 kernel 里面的等待队列,在前面那篇 ioctl 的文章里有详细说明,它现在阻塞于 proc->wait 这个变量,如果唤醒 proc->wait 阻塞会结束。还有如果后面那个 binder_has_proc_work 返回值为 1(条件为 true) 阻塞也会结束。但是这里 binder_has_proc_work 不为 true:
1
2
3
4
5
6
7
8
static int binder_has_proc_work(struct binder_proc *proc,
struct binder_thread *thread)
{
return !list_empty(&proc->todo) ||
(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN);
}
所以这里 binder_thread_read 要不阻塞,要么跑进来的时候 proc->todo 不为空(就是该进程有需要处理的工作),要么就只能等待有人唤醒 proc->wait 。这里对应图中 service 在等待客户端请求的到来,这个是在 kernel 中使用 wait queue(等待队列)实现的。
所以为什么先处理 binder_thread_write ,因为 binder_thread_read 会阻塞。
2. 客户端发起 IPC 请求
服务端已经在阻塞等待了,现在来看看客户端(client)这边(图中的左边部分)。client 调用一个 IPC 接口函数(例如调用 ActivityManager 的 startActivity 之类的),发起 IPC 调用,IPC 接口函数调用 Bp 的 transaction 函数,这些在前面的原理篇里有说过,获取 Bp 是通过 service manager 获取的(前面说 service 要在 service manager 注册就是为了 client 能通过 service manager 获取自己的 Bp),这里细节后面再说。
Bp 的 transaction 直接调用 IPCThreadState 的 transaction 函数(注意别头晕,servie、client 是共用一份代码的,加上前面 ioctl 读、写一个命令 -_-||):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
status_t err = data.errorCheck();
flags |= TF_ACCEPT_FDS;
IF_LOG_TRANSACTIONS() {
TextOutput::Bundle _b(alog);
alog << "BC_TRANSACTION thr " << (void *)pthread_self() << " / hand "
<< handle << " / code " << TypeCode(code) << ": "
<< indent << data << dedent << endl;
}
if (err == NO_ERROR) {
LOG_ONEWAY(">>>> SEND from pid %d uid %d %s" , getpid(), getuid(),
(flags & TF_ONE_WAY) == 0 ? "READ REPLY" : "ONE WAY" );
err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);
}
if (err != NO_ERROR) {
if (reply) reply->setError(err);
return (mLastError = err);
}
if ((flags & TF_ONE_WAY) == 0 ) {
#if 0
if (code == 4 ) {
ALOGI(">>>>>> CALLING transaction 4" );
} else {
ALOGI(">>>>>> CALLING transaction %d" , code);
}
#endif
if (reply) {
err = waitForResponse(reply);
} else {
Parcel fakeReply;
err = waitForResponse(&fakeReply);
}
#if 0
if (code == 4 ) {
ALOGI("<<<<<< RETURNING transaction 4" );
} else {
ALOGI("<<<<<< RETURNING transaction %d" , code);
}
#endif
IF_LOG_TRANSACTIONS() {
TextOutput::Bundle _b(alog);
alog << "BR_REPLY thr " << (void *)pthread_self() << " / hand "
<< handle << ": " ;
if (reply) alog << indent << *reply << dedent << endl;
else alog << "(none requested)" << endl;
}
} else {
err = waitForResponse(NULL, NULL);
}
return err;
}
这里也是分为2个部分:第一部分: writeTransactionData 向 service 写请求数据,第二部分: waitForResponse,等待 service 返回请求结果。不难理解,一个函数调用,一般都有返回值(就算是 void 的也需要等待 service 返回结果),所以要发起请求后,要等待 service 返回结果。
先来看下写请求数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags,
int32_t handle, uint32_t code, const Parcel& data, status_t* statusBuffer)
{
binder_transaction_data tr;
tr.target.handle = handle;
tr.code = code;
tr.flags = binderFlags;
tr.cookie = 0 ;
tr.sender_pid = 0 ;
tr.sender_euid = 0 ;
const status_t err = data.errorCheck();
if (err == NO_ERROR) {
tr.data_size = data.ipcDataSize();
tr.data.ptr.buffer = data.ipcData();
tr.offsets_size = data.ipcObjectsCount()*sizeof (size_t);
tr.data.ptr.offsets = data.ipcObjects();
} else if (statusBuffer) {
tr.flags |= TF_STATUS_CODE;
*statusBuffer = err;
tr.data_size = sizeof (status_t);
tr.data.ptr.buffer = statusBuffer;
tr.offsets_size = 0 ;
tr.data.ptr.offsets = NULL;
} else {
return (mLastError = err);
}
mOut.writeInt32(cmd);
mOut.write(&tr, sizeof (tr));
return NO_ERROR;
}
传过去的 cmd(命令)是 BC_TRANSACTION 这个要记住。这里把上层 app 传递过来的数据(Pacrel 封装的,主要是 IPC 的参数),打包到 binder_transaction_data 这个数据结构中,这个是 kernel binder 驱动 ioctl 参数里带的数据(后面再说)。这里都是通过 mOut Pacrel 打包的(后面再说)。注意这里只是把数据包打好,还没发送。
然后到 IPCThreadState transaction 的第二部分:waitForResponse 等待 service 返回处理结果。这里注意一下 transaction 有个判断:
if ((flags & TF_ONE_WAY) == 0)
这个是表示 IPC 调用需要不需要返回,一般都是需要的,所以这里 waitForResponese 的参数 reply 不是 NULL,这个 reply 会返回给 IPC 的调用者,里来带有返回的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
int32_t cmd;
int32_t err;
while (1 ) {
if ((err=talkWithDriver()) < NO_ERROR) break ;
... ...
}
}
这里看到有一个循环,至于为什么,到后面会知道的。循环开始调用 talkWithDriver,这个函数前面在 service 那里看过了,是调用 ioctl 去 bidner 那里写数据和读数据。service 那里只是读了,但是没写。client 不一样了,前面 writeTransactionData 把 BC_TRANSACTION 命令和参数全都打包好了,就通过 ioctl 发到 kernel 的 binder 那去了。
这里 binder_ioctl 那会跑 binder_thread_write 了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed)
{
uint32_t cmd;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof (uint32_t);
if (_IOC_NR(cmd) < ARRAY_SIZE(binder_stats.bc)) {
binder_stats.bc[_IOC_NR(cmd)]++;
proc->stats.bc[_IOC_NR(cmd)]++;
thread->stats.bc[_IOC_NR(cmd)]++;
}
switch (cmd) {
... ...
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
if (copy_from_user(&tr, ptr, sizeof (tr)))
return -EFAULT;
ptr += sizeof (tr);
binder_transaction(proc, thread, &tr, cmd == BC_REPLY);
break ;
}
... ...
default :
printk(KERN_ERR "binder: %d:%d unknown command %d\n" ,
proc->pid, thread->pid, cmd);
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0 ;
}
write 这里是一个 while 循环 ptr 是前面用户空间(client)打包传进入来的数据,end 是数据结束的地址。这么搞这一个循环,其实是因为这个数据是支持打包多条命令的,虽然这里没体现出来,但是后面有些地方能体现出来,例如说释放内存的命令有些时候就是和其其它命令打包在一起传进来的。取完数据,数据指针会移动,移动到 end 地址了,就结束处处理了,所以可以处理多条命令。感觉 binder 这里经常一次搞多种东西,让代码上让人感觉怪怪的。主要看用的人了,因为是支持打包多条命令的。
不过这里先关心我们之前 client 写入的 BC_TRANSACTION 命令。看下面的处理的处理。传输命令交由 binder_transaction 函数处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
struct binder_transaction *t;
struct binder_work *tcomplete;
size_t *offp, *off_end;
struct binder_proc *target_proc;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct list_head *target_list;
wait_queue_head_t *target_wait;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
uint32_t return_error;
e = binder_transaction_log_add(&binder_transaction_log);
e->call_type = reply ? 2 : !!(tr->flags & TF_ONE_WAY);
e->from_proc = proc->pid;
e->from_thread = thread->pid;
e->target_handle = tr->target.handle;
e->data_size = tr->data_size;
e->offsets_size = tr->offsets_size;
if (reply) {
... ...
} else {
if (tr->target.handle) {
struct binder_ref *ref;
ref = binder_get_ref(proc, tr->target.handle);
if (ref == NULL) {
binder_user_error("binder: %d:%d got "
"transaction to invalid handle\n" ,
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_invalid_target_handle;
}
target_node = ref->node;
} else {
target_node = binder_context_mgr_node;
if (target_node == NULL) {
return_error = BR_DEAD_REPLY;
goto err_no_context_mgr_node;
}
}
e->to_node = target_node->debug_id;
target_proc = target_node->proc;
if (target_proc == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
struct binder_transaction *tmp;
tmp = thread->transaction_stack;
if (tmp->to_thread != thread) {
binder_user_error("binder: %d:%d got new "
"transaction with bad transaction stack"
", transaction %d has target %d:%d\n" ,
proc->pid, thread->pid, tmp->debug_id,
tmp->to_proc ? tmp->to_proc->pid : 0 ,
tmp->to_thread ?
tmp->to_thread->pid : 0 );
return_error = BR_FAILED_REPLY;
goto err_bad_call_stack;
}
while (tmp) {
if (tmp->from && tmp->from->proc == target_proc)
target_thread = tmp->from;
tmp = tmp->from_parent;
}
}
}
if (target_thread) {
e->to_thread = target_thread->pid;
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {
target_list = &target_proc->todo;
target_wait = &target_proc->wait;
}
e->to_proc = target_proc->pid;
... ...
}
先来看看这个函数前面一段,前面有一个是否是 reply 的判断,前面 BC_TRANSACTION 命令传过来的是 true,所以走的下面分支。其实这段是查找服务端进程的。tr->target.handle 这个由最开始 client 所持有的 Bp 传进来的,通过这个 kernel binder 驱动可以找对应的 service 的 proc。这里具体后面再说,这里就简单知道通过 handle 找到远程目标 service 的 proc,还有这里走的是下面 target_proc 的分支,target_thread 是后面 service 写返回值用的。还有注意,这里通过找到 target_proc 确定了 target_wait,回想下前面 service 在 binder_thread_read 那里 wait,就是 wait 这个变量。
接下去继续往下看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
t = kzalloc(sizeof (*t), GFP_KERNEL);
if (t == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_t_failed;
}
binder_stats_created(BINDER_STAT_TRANSACTION);
tcomplete = kzalloc(sizeof (*tcomplete), GFP_KERNEL);
if (tcomplete == NULL) {
return_error = BR_FAILED_REPLY;
goto err_alloc_tcomplete_failed;
}
binder_stats_created(BINDER_STAT_TRANSACTION_COMPLETE);
t->debug_id = ++binder_last_id;
e->debug_id = t->debug_id;
int tmp_pid = -1 ;
if (target_thread) {
tmp_pid = target_thread->pid;
}
... ...
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = proc->tsk->cred->euid;
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
t->priority = task_nice(current);
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
if (t->buffer == NULL) {
return_error = BR_FAILED_REPLY;
goto err_binder_alloc_buf_failed;
}
t->buffer->allow_user_free = 0 ;
t->buffer->debug_id = t->debug_id;
t->buffer->transaction = t;
t->buffer->target_node = target_node;
if (target_node)
binder_inc_node(target_node, 1 , 0 , NULL);
offp = (size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof (void *)));
if (copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"data ptr\n" , proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
if (copy_from_user(offp, tr->data.ptr.offsets, tr->offsets_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"offsets ptr\n" , proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
if (!IS_ALIGNED(tr->offsets_size, sizeof (size_t))) {
binder_user_error("binder: %d:%d got transaction with "
"invalid offsets size, %zd\n" ,
proc->pid, thread->pid, tr->offsets_size);
return_error = BR_FAILED_REPLY;
goto err_bad_offset;
}
off_end = (void *)offp + tr->offsets_size;
for (; offp < off_end; offp++) {
... ...
}
if (reply) {
BUG_ON(t->buffer->async_transaction != 0 );
binder_pop_transaction(target_thread, in_reply_to);
} else if (!(t->flags & TF_ONE_WAY)) {
BUG_ON(t->buffer->async_transaction != 0 );
t->need_reply = 1 ;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
} else {
BUG_ON(target_node == NULL);
BUG_ON(t->buffer->async_transaction != 1 );
if (target_node->has_async_transaction) {
target_list = &target_node->async_todo;
target_wait = NULL;
} else
target_node->has_async_transaction = 1 ;
}
t->work.type = BINDER_WORK_TRANSACTION;
list_add_tail(&t->work.entry, target_list);
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
list_add_tail(&tcomplete->entry, &thread->todo);
if (target_wait)
wake_up_interruptible(target_wait);
return ;
这里创建了2个对象:binder_transaction 和 binder_work,后面的代码就是填充这2个结构。binder_transaction 主要是把目标(target_proc 或是 traget_thread)和数据填写好。数据从用户层 ioctl 传过来的 binder_transaction_data(前面 client writeTransactionData 那里),把 IPC 的参数打包封装起来了,这里通过 copy_from_user 把这里数据再填写到 binder_transaction 带的数据结构的指针中。
这里还有一点,保存了传递堆栈,!(t->flags & TF_ONE_WAY) 这里一般 IPC 都是需要返回的,所以把当前的 binder_transaction 保存到 transaction_stack 中去了。后面 service 写返回值的时候回通过这个找到要返回的目标进程的。
最后, binder_transaction 的 work type 设置为 BINDER_WORK_TRANSACTION 然后 binder_work 设置为 BINDER_WORK_TRANSACTION_COMPLETE ,分别加入到了 target_list 中(这个这里是 target_proc 的 todo list,也就是 service 的进程工作列表)和 thread 的 todo list(也就是 client 发起 IPC 调用的线程的 todo list)。然后,如果目标 service 进程在等待中(前面第一部分确实在等待),就唤醒它。(回去看看最开始的图稍微好理解些)
其实到这里,client 已经把 IPC 请求发出去了,而 service 那把阻塞在 binder_thread_read 那里的也应该唤醒了,开始执行后面的处理了。不过这里还是继续看 client 这边。
client 这边 binder_thread_write 处理完了,就到 binder_thread_read 了。前面 service 那里分析过阻塞的情况(前面说过了 service、client 代码都是共用的)。这里因为前面 binder_thread_write 那里把一个 binder_work 插入到 thread->todo 中,所以这里是不会阻塞的。这里会不会觉得有点奇怪,应该正常的模型应该是要阻塞等待 service 那边返回结果才对,不过先别着急。慢慢看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
while (1 ) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
if (!list_empty(&thread->todo))
w = list_first_entry(&thread->todo, struct binder_work, entry);
else if (!list_empty(&proc->todo) && wait_for_proc_work)
w = list_first_entry(&proc->todo, struct binder_work, entry);
else {
if (ptr - buffer == 4 && !(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN))
goto retry;
break ;
}
if (end - ptr < sizeof (tr) + 4 )
break ;
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work);
} break ;
case BINDER_WORK_TRANSACTION_COMPLETE: {
cmd = BR_TRANSACTION_COMPLETE;
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof (uint32_t);
binder_stat_br(proc, thread, cmd);
binder_debug(BINDER_DEBUG_TRANSACTION_COMPLETE,
"binder: %d:%d BR_TRANSACTION_COMPLETE\n" ,
proc->pid, thread->pid);
list_del(&w->entry);
kfree(w);
binder_stats_deleted(BINDER_STAT_TRANSACTION_COMPLETE);
} break ;
... ...
}
if (!t)
continue ;
... ...
}
有是一个 while 循环,前面已经有好多了,见怪不怪。前面把一个 BINDER_WORK_TRANSACTION_COMPLETE 的 binder_work 插入到了 thread->todo 中,所以这里的分支是 switch 那里的 BINDER_WORK_TRANSACTION_COMPLETE 。这里只是把一个 BR_TRANSACTION_COMPLETE 返回给用户了(put_user 是 kernel 向用户空间写单个变量,copy_user 是传递一片数据)。然后就把这个 work 从 todo list 中删掉了。
然后走到下面,t 是 NULL 所以又回到循环开始地方,由于处理完了 work 就删掉了,所以这里取不到任何 todo work 了,就会走最后没那个 else 分支,然后这个(ptr - buffer == 4 && !(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN))
这个判断是没有任何读数据的时候,就是没做任何处理。前面最开始有向用户空间写入 BR_NOOP 的操作(可以回到 service 那里仔细看一下),所以如果没做任何处理, ptr 应该被移动了4个字节。但是前面处理了 BINDER_WORK_TRANSACTION_COMPLETE 有移动了4个字节,所以这里条件不满足。然后就 break 跳出循环了。然后 binder_thread_read 就结束了。这次 ioctl 也就结束了,然后又回到用户空间 client 那里。
这里会到前面 client waitForResponse 那里,从 talkWithDrvier 返回了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
while (1 ) {
if ((err=talkWithDriver()) < NO_ERROR) break ;
err = mIn.errorCheck();
if (err < NO_ERROR) break ;
if (mIn.dataAvail() == 0 ) continue ;
cmd = mIn.readInt32();
IF_LOG_COMMANDS() {
alog << "Processing waitForResponse Command: "
<< getReturnString(cmd) << endl;
}
switch (cmd) {
case BR_TRANSACTION_COMPLETE:
if (!reply && !acquireResult) goto finish;
break ;
... ...
default :
err = executeCommand(cmd);
if (err != NO_ERROR) goto finish;
break ;
}
}
finish:
if (err != NO_ERROR) {
if (acquireResult) *acquireResult = err;
if (reply) reply->setError(err);
mLastError = err;
}
前面 kernel binder_thread_read 返回的 cmd 是 BR_TRANSACTION_COMPLETE ,这边分支除了一个判断,要跳转到 finish 以外其它什么处理都没了。前面 client waitForResponse 是有传入参数 reply 的(这个是拿来存 IPC 函数的返回值的),所以这里只是 break 而已,没跳转去 finish(跳转到 finish 这个函数就结束了)。如果是不需要返回的,reply 传入 NULL 的话,接收到 kernel 的返回值,就直接退出了。
从这个含义来看, BR_TRANSACTION_COMPLETE 是 kernel binder 告诉调用者,命令发送已经处理完毕(前面 client 有对 kernel 发送 BC_TRANSACTION 命令)。所以 kernel 会把 BINDER_WORK_TRANSACTION_COMPLETE 的 work 插入到本线程的 todo list 中,为了就是告诉调用者,发送已经完成而已。而看样子,现阶段这个返回值好像没啥用,因为调用者没做啥处理。这个理解下设计者的意图,后面 service 还会有。
然后继续循环,然后调用 talkWithDriver,这里和前面第一部分 service 那里很像,因为前面把 mOut 中数据已经写完了,所以这里写入就是 0byte,读入 256btye,然后就和前面 service 一样了,阻塞在 binder_thread_read 那里等待 service 返回的值。这里才是符合前面所的模型,client 发送了请求后,就要等待 service 的返回。这里是通过 client 那里 waitForResponse 的 while 来实现的,因为这个函数需要处理多个命令(kernel 的返回值),这里知道为什么这里要用循环了吧。
3. 服务端处理请求,并返回结果
client 在等待 service 的处理,我们回到 service 这边。之前 service 阻塞在 binder_thread_read 的 ioctl 调用那(回到图中右边部分),后面 client 发送了一个 IPC 请求,然后把一个 work 插入到了 service proc(target_proc) 的 todo lsit 上,service 的阻塞就被唤醒了。我们接着看后面的处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
while (1 ) {
... ...
BUG_ON(t->buffer == NULL);
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
t->saved_priority = task_nice(current);
if (t->priority < target_node->min_priority &&
!(t->flags & TF_ONE_WAY))
binder_set_nice(t->priority);
else if (!(t->flags & TF_ONE_WAY) ||
t->saved_priority > target_node->min_priority)
binder_set_nice(target_node->min_priority);
cmd = BR_TRANSACTION;
} else {
tr.target.ptr = NULL;
tr.cookie = NULL;
cmd = BR_REPLY;
}
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = t->sender_euid;
if (t->from) {
struct task_struct *sender = t->from->proc->tsk;
tr.sender_pid = task_tgid_nr_ns(sender,
current->nsproxy->pid_ns);
} else {
tr.sender_pid = 0 ;
}
tr.data_size = t->buffer->data_size;
tr.offsets_size = t->buffer->offsets_size;
tr.data.ptr.buffer = (void *)t->buffer->data +
proc->user_buffer_offset;
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof (void *));
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof (uint32_t);
if (copy_to_user(ptr, &tr, sizeof (tr)))
return -EFAULT;
ptr += sizeof (tr);
binder_stat_br(proc, thread, cmd);
binder_debug(BINDER_DEBUG_TRANSACTION,
"binder: %d:%d %s %d %d:%d, cmd %d"
"size %zd-%zd ptr %p-%p\n" ,
proc->pid, thread->pid,
(cmd == BR_TRANSACTION) ? "BR_TRANSACTION" :
"BR_REPLY" ,
t->debug_id, t->from ? t->from->proc->pid : 0 ,
t->from ? t->from->pid : 0 , cmd,
t->buffer->data_size, t->buffer->offsets_size,
tr.data.ptr.buffer, tr.data.ptr.offsets);
list_del(&t->work.entry);
t->buffer->allow_user_free = 1 ;
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;
} else {
t->buffer->transaction = NULL;
kfree(t);
binder_stats_deleted(BINDER_STAT_TRANSACTION);
}
break ;
}
由于 client 把一个 work 插入到 service proc 中的 todo list 中, work type 是 BINDER_WORK_TRANSACTION,这个处理就自己把前面写入的 binder_transaction 这个数据结构给取出来了,所以 t 那个判断 t != NULL 就会继续走下面的处理(看前面 client 的代码分析)。
这里有个分支判断: t->buffer->target_node 是否为 NULL,前面 client binder_transaction 那里通过 Bp 的 handle 找到了目标(service)的 target node 了的(每个 Bn 都是一个 binder node,这个后面再说),然后把 target_node 写入了 binder_transaction 中,所以这里走 BR_TRANSACTION 命令这个分支。这个分支把 target_node 的 ptr 和 cookie 写了返回给 service 的数据中,这个东西就是 Bn 的地址指针(这个后面 service manager 那再具体说)。
然后下面,就是把 binder_transaction 中的数据地址 copy 到准备返回给 service 的 binder_transaction_data 中。然后先是一个 put_user 把 BR_TRANSACTION 命令写给用户空间,后面 copy_to_user 把数据给写给用户空间。最后分支是 BR_TRANSACTION 然后也需要返回,保存下传送堆栈。
之后 service 在 kernel 中的 ioctl 阻塞结束,返回到用户空间。之前在 getAndExecuteCommand 的 talkWithDriver 阻塞,现在继续往下执行,在 ioctl 读取到数据后,读取 kernel 返回的命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
if (result >= NO_ERROR) {
size_t IN = mIn.dataAvail();
if (IN < sizeof (int32_t)) return result;
cmd = mIn.readInt32();
IF_LOG_COMMANDS() {
alog << "Processing top-level Command: "
<< getReturnString(cmd) << endl;
}
result = executeCommand(cmd);
set_sched_policy(mMyThreadId, SP_FOREGROUND);
}
之前 kernel 返回的是 BR_TRANSACTION,然后到 executeCommand 处理命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
status_t IPCThreadState::executeCommand(int32_t cmd)
{
BBinder* obj;
RefBase::weakref_type* refs;
status_t result = NO_ERROR;
switch (cmd) {
... ...
case BR_TRANSACTION:
{
binder_transaction_data tr;
result = mIn.read(&tr, sizeof (tr));
ALOG_ASSERT(result == NO_ERROR,
"Not enough command data for brTRANSACTION" );
if (result != NO_ERROR) break ;
Parcel buffer;
buffer.ipcSetDataReference(
reinterpret_cast <const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast <const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof (size_t), freeBuffer, this );
const pid_t origPid = mCallingPid;
const uid_t origUid = mCallingUid;
mCallingPid = tr.sender_pid;
mCallingUid = tr.sender_euid;
int curPrio = getpriority(PRIO_PROCESS, mMyThreadId);
if (gDisableBackgroundScheduling) {
if (curPrio > ANDROID_PRIORITY_NORMAL) {
setpriority(PRIO_PROCESS, mMyThreadId, ANDROID_PRIORITY_NORMAL);
}
} else {
if (curPrio >= ANDROID_PRIORITY_BACKGROUND) {
set_sched_policy(mMyThreadId, SP_BACKGROUND);
}
}
Parcel reply;
IF_LOG_TRANSACTIONS() {
TextOutput::Bundle _b(alog);
alog << "BR_TRANSACTION thr " << (void *)pthread_self()
<< " / obj " << tr.target.ptr << " / code "
<< TypeCode(tr.code) << ": " << indent << buffer
<< dedent << endl
<< "Data addr = "
<< reinterpret_cast <const uint8_t*>(tr.data.ptr.buffer)
<< ", offsets addr="
<< reinterpret_cast <const size_t*>(tr.data.ptr.offsets) << endl;
}
if (tr.target.ptr) {
sp<BBinder> b((BBinder*)tr.cookie);
const status_t error = b->transact(tr.code, buffer, &reply, tr.flags);
if (error < NO_ERROR) reply.setError(error);
} else {
const status_t error = the_context_object->transact(tr.code, buffer, &reply, tr.flags);
if (error < NO_ERROR) reply.setError(error);
}
if ((tr.flags & TF_ONE_WAY) == 0 ) {
LOG_ONEWAY("Sending reply to %d!" , mCallingPid);
sendReply(reply, 0 );
} else {
LOG_ONEWAY("NOT sending reply to %d!" , mCallingPid);
}
mCallingPid = origPid;
mCallingUid = origUid;
IF_LOG_TRANSACTIONS() {
TextOutput::Bundle _b(alog);
alog << "BC_REPLY thr " << (void *)pthread_self() << " / obj "
<< tr.target.ptr << ": " << indent << reply << dedent << endl;
}
}
break ;
default :
printf ("*** BAD COMMAND %d received from Binder driver\n" , cmd);
result = UNKNOWN_ERROR;
break ;
}
if (result != NO_ERROR) {
mLastError = result;
}
return result;
}
继续从 mIn 中把前面 kernel 写入的 binder_transaction_data 数据取出来,然后把 buffer 数据地址写入到 Parcel 中,这个相当于把 client 传入的 IPC 参数取出来了。
然后关键的来了, 判断 tr.target.ptr 是否为 NULL,前面 kernel 把 service Bn 的指针地址写进去了,后面直接转化为 BBinder* ,然后调用 transaction 方法。这个就想当于调用 serivce Bn 的 transaction 方法,最后参数调用到 service 中真正实现的函数,具体的看前一篇原理的分析(这里实现 IPC 调用,前面图中有一个流程 impl IPC API)。
在调用 transaction 的时候,有个引用参数 reply,service 的业务函数会把返回值通过 Parcel 打包好,然后后面那个判断前面见过很多次,是需要返回值的,所以调用 sendReply 把返回值,通过 kernel binder 发送给 client:
1
2
3
4
5
6
7
8
9
10
status_t IPCThreadState::sendReply(const Parcel& reply, uint32_t flags)
{
status_t err;
status_t statusBuffer;
err = writeTransactionData(BC_REPLY, flags, -1 , 0 , reply, &statusBuffer);
if (err < NO_ERROR) return err;
return waitForResponse(NULL, NULL);
}
这个函数十分简洁,调用的2个函数前面(client 发命令那里)也都见过,而且顺序都一样,只不过参数不一样而已。writeTransactionData 打包的命令是 BC_REPLY,而 waitForReponse 参数是 NULL,根据前面的分析,参数是 NULL 的话,那么得到 kernel 返回 BR_TRANSACTION_COMPLETE 函数就结束了(前面的图中是 no reply)。
这里就不贴代码了,和前面是一样的,writeTransactionData 把数据打好包后,waitForReponse 通过 talkWithDriver 的 ioctl 就到 kernel 里面了,这次 binder_thread_write 调用 binder_transaction 的参数 reply 是 true,来看看有什么不一样(前面 client 是 false):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
if (reply) {
in_reply_to = thread->transaction_stack;
if (in_reply_to == NULL) {
binder_user_error("binder: %d:%d got reply transaction "
"with no transaction stack\n" ,
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_empty_call_stack;
}
binder_set_nice(in_reply_to->saved_priority);
if (in_reply_to->to_thread != thread) {
binder_user_error("binder: %d:%d got reply transaction "
"with bad transaction stack,"
" transaction %d has target %d:%d\n" ,
proc->pid, thread->pid, in_reply_to->debug_id,
in_reply_to->to_proc ?
in_reply_to->to_proc->pid : 0 ,
in_reply_to->to_thread ?
in_reply_to->to_thread->pid : 0 );
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
goto err_bad_call_stack;
}
thread->transaction_stack = in_reply_to->to_parent;
target_thread = in_reply_to->from;
if (target_thread == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
if (target_thread->transaction_stack != in_reply_to) {
binder_user_error("binder: %d:%d got reply transaction "
"with bad target transaction stack %d, "
"expected %d\n" ,
proc->pid, thread->pid,
target_thread->transaction_stack ?
target_thread->transaction_stack->debug_id : 0 ,
in_reply_to->debug_id);
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
target_thread = NULL;
goto err_dead_binder;
}
target_proc = target_thread->proc;
} else {
... ...
}
这里主要的不同是寻找目标进程(线程)的不同,前面 client 那里寻找目标 service proc 是通过从 service manager 取到的 service Bp 的 handle 取到 service Bn 的 node,进而找到 service proc 的。这里却是通过前面 client 保存的 transaction_stack(传送堆栈)取到要返回的 client 的 thread 的。而且还根据这个校验这次的传送是否是有效的,就是保存的堆栈中的 in_reply_to 必须是本线程(就是前面 client 发送到的目标线程序必须是自己),否则就认为是一次无效的调用,就不处理(这个可能对某些恶意注入、拦截有用吧)。
然后后面就和 client 那里一样了,创建 binder_transaction 和 binder_work 把数据和 work type 写到里面去。有一点,后面如果是 reply 则调用 binder_pop_transaction 把之前 client 保存堆栈出栈(因为这里是返回到 client,所以要出栈,之前 client 到 service 是入栈)。
然后也和前面 client 一样,插入了2个 work,一个插到 client 的 thread todo (这里是 thread 的 todo list,因为前面找到的 target_thread != NULL)里面,一个插到自己 thread 的 todo 里面,并唤醒在等待的 client 线程。
这里和前面一样,先不管 client 那边先,先继续看 service 这边。这边从 binder_thread_write 写完后,就到 binder_thread_read 了。和前面 client 一样,由于插入了 BINDER_WORK_COMPLETE 的 work 到 thread->todo list 所以这里不会阻塞。然后和 client 一样了,返回 BR_TRANSACTION_COMPLETE 给用户空间,然后退出循环,结束 ioctl 调用。
到用户空间, waitForReponse 前面说了,参数为 NULL,直接跳到 finish,结束,然后 sendReply 执行结束, exectueCommand 执行结束,然后 getAndExecuteCommand 执行结束。这里本次 IPC 调用, service 端的工作就算是结束了。然后进入下一个 joinThreadLoop 循环,等待下一次 client 请求的到来。
4. 客户端接收到服务端返回的数据
service 端结束了,回到 client 这边(继续图的左边部分)。前面 client 为等待 service 返回的结果,阻塞在 binder_thread_read 那里。上一个部分, service 把返回数据用 BC_REPLY 写入 kernel 后,client 就被唤醒了,然后继续往下走:
1
2
3
4
5
6
7
8
9
10
BUG_ON(t->buffer == NULL);
if (t->buffer->target_node) {
... ...
} else {
tr.target.ptr = NULL;
tr.cookie = NULL;
cmd = BR_REPLY;
}
前面取数据都一样了,然后主要是这里不一样,前面 service 那 t->buffer->target_node 是为 NULL 的,但是这里是 NULL(上面一部 service 是通过 transaction_stack 取的 target thread,所以没有 target_node),所以走下面。Bn 的地址直接设置为 NULL(client 那当然没 Bn,那里的是 Bp),返回的命令的是 BR_REPLY 。后面的处理就和前面差不多了,方法就返回到用户空间了。
这里就从 talkWithDriver 回到了 waitForReponse ,继续下面的处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
while (1 ) {
if ((err=talkWithDriver()) < NO_ERROR) break ;
err = mIn.errorCheck();
if (err < NO_ERROR) break ;
if (mIn.dataAvail() == 0 ) continue ;
cmd = mIn.readInt32();
IF_LOG_COMMANDS() {
alog << "Processing waitForResponse Command: "
<< getReturnString(cmd) << endl;
}
switch (cmd) {
... ...
case BR_REPLY:
{
binder_transaction_data tr;
err = mIn.read(&tr, sizeof (tr));
ALOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY" );
if (err != NO_ERROR) goto finish;
if (reply) {
if ((tr.flags & TF_STATUS_CODE) == 0 ) {
reply->ipcSetDataReference(
reinterpret_cast <const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast <const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof (size_t),
freeBuffer, this );
} else {
err = *static_cast <const status_t*>(tr.data.ptr.buffer);
freeBuffer(NULL,
reinterpret_cast <const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast <const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof (size_t), this );
}
} else {
freeBuffer(NULL,
reinterpret_cast <const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast <const size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof (size_t), this );
continue ;
}
}
goto finish;
default :
err = executeCommand(cmd);
if (err != NO_ERROR) goto finish;
break ;
}
}
finish:
if (err != NO_ERROR) {
if (acquireResult) *acquireResult = err;
if (reply) reply->setError(err);
mLastError = err;
}
这里从 kernel 返回的命令是 BR_REPLY,处理也比较简单,就是把 service 写给 kernel 的数据指针设置给了 reply (Parcel)而已。然后就跳出循环 finish 了。然后后面就是通过 Parcel 从 reply 中读出 service 打包的数据,作为函数的返回值。
到这里 client 发起的一次 IPC 调用就结束了。
总结
前面写了很多,稍微简化一下流程是:
service 运行,阻塞于 ioctl,等待 client 发起请求
client 通过 ioctl 发起 IPC 请求,等待 service 结果BC_TRANSACTIONBR_TRANSACTION_COMPLETE
service 被唤醒,完成业务,返回结果BR_TRANSACTIONBC_REPLYBR_TRANSACTION_COMPLETE
client 被唤醒,读取 service 返回结果, IPC 结束BR_REPLY
可以看到 BC 开头的协议都是用户空间对 kernel 发送的, BR 开头的协议都是 kernel 返回给用户空间的。所以应用程序是通过 kernel 的 binder 驱动进行通信的(之前我搞混过,一开始我以为这些 BC_XX, BR_XX 是 client 发往 service,其实不是它们都只与 kernel 通信而已,不知道对方彼此的存在)。向 kernel 发送传送请求的命令(BC_TRANSACTION, BC_REPLY),kernel 会返回 BR_TRANSACTION_COMPLETE 告诉发送者,传送完成。
kernel binder 驱动 binder.h 中定义2个 enum ,分别是: BinderDriverReturnProtocol 和 BinderDriverCommandProtocol 。里面除了上面提到的 BC_TRANSACTION, BC_REPLY, BR_TRANSACTION_COMPLETE, BR_TRANSACTION, BR_REPLY 还有很多别的命令,而且有一些还是没实现的(看注释有写)。其它一些用处,后面一些篇章会说到。其实名字还是挺形象的(BC、BR),只不过我一开始理解错了。