前面分析了 binder 中用来打包、传递数据的 Parcel,一般用来传递 IPC 中的小型参数和返回值。binder 目前每个进程 mmap 接收数据的内存是 1M,所以就算你不考虑效率问题用 Parcel 来传,也无法传过去。只要超过 1M 就会报错(binder 无法分配接收空间)。所以 android 里面有一个专门用来在 IPC 中传递大型数据的东西—— Ashmem(Anonymous Shared Memroy)。照例把相关代码的位置说一下(4.4):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
frameworks/base/core/java/os/Parcel.java
frameworks/base/core/java/os/Parcelable.java
frameworks/base/core/java/os/ParcelFileDescriptor.java
frameworks/base/core/java/os/MemoryFile.java
frameworks/base/core/jni/android_os_Parcel.h
frameworks/base/core/jni/android_os_MemoryFile.cpp
frameworks/base/core/jni/android_os_Parcel.cpp
libnativehelper/JNIHelp.cpp
system/core/include/cutils/ashmem.h
system/core/libcutils/ashmem-dev.c
frameworks/native/include/binder/Parcel.h
frameworks/native/include/binder/IMemory.h
frameworks/native/include/binder/MemoryHeapBase.h
frameworks/native/include/binder/MemoryBase.h
frameworks/native/libs/binder/Parcel.cpp
frameworks/native/libs/binder/Memory.cpp
frameworks/native/libs/binder/MemoryHeapBase.cpp
frameworks/native/libs/binder/MemoryBase.cpp
kernel/drivers/staging/android/binder.h
kernel/drivers/staging/android/binder.c
kernel/include/linux/ashmem.h
kernel/mm/ashmem.c
(这和 Parcel 篇的基本一样么 -_-||)
原理概述
ashmem 并像 binder 是 android 重新自己搞的一套东西,而是利用了 linux 的 tmpfs 文件系统。关于 tmpfs 我目前还不算很了解,可以先看下这里的2篇,有个基本的了解:
Linux tmpfs linux共享内存的设计
那么大致能够知道,tmpfs 是一种可以基于 ram 或是 swap 的高速文件系统,然后可以拿它来实现不同进程间的内存共享。
然后大致思路和流程是:
Proc A 通过 tmpfs 创建一块共享区域,得到这块区域的 fd(文件描述符)
Proc A 在 fd 上 mmap 一片内存区域到本进程用于共享数据
Proc A 通过某种方法把 fd 倒腾给 Proc B
Proc B 在接到的 fd 上同样 mmap 相同的区域到本进程
然后 A、B 在 mmap 到本进程中的内存中读、写,对方都能看到了
其实核心点就是创建一块共享区域,然后2个进程同时把这片区域 mmap 到本进程,然后读写就像本进程的内存一样。这里要解释下第3步,为什么要倒腾 fd,因为在 linux 中 fd 只是对本进程是唯一的,在 Proc A 中打开一个文件得到一个 fd,但是把这个打开的 fd 直接放到 Proc B 中,Proc B 是无法直接使用的。但是文件是唯一的,就是说一个文件(file)可以被打开多次,每打开一次就有一个 fd(文件描述符),所以对于同一个文件来说,需要某种转化,把 Proc A 中的 fd 转化成 Proc B 中的 fd。这样 Proc B 才能通过 fd mmap 同样的共享内存文件(额,其实这里相关知识我也还没了解,瞎扯一下)。
java 层接口
java 层的接口要拿 2.3 的来说,因为从 4.1(具体哪个版本我不好说,反正我手上只有 4.1 之后的)之后 java 层的 MemroyFile 应该就无法正常使用了,搜索代码发现,除了 test 有 MemroyFile 其它地方就去掉了。具体原因后面分析代码就知道了。
咋先来点感性的认识(MemroyFile.java):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
private FileDescriptor mFD;
private int mAddress;
private int mLength;
private boolean mAllowPurging = false ;
private final boolean mOwnsRegion;
public MemoryFile (String name, int length) throws IOException {
mLength = length;
mFD = native_open(name, length);
mAddress = native_mmap(mFD, length, PROT_READ | PROT_WRITE);
mOwnsRegion = true ;
}
MemroyFile 还是比较简单的,成员变量也比较少,上面基本上就是所有的变量了。FileDescriptor 这个是 java 本身的对象,应该是 natvie fd 的封装吧。后面的地址、长度不说了。后面2个 boolean, mAllowPurging 表示这块 ashmem 是否允许被回收。 ashmem 在驱动那向 kernel 注册了一个内存回收算法,当 kernel 进行内存扫描的时候会调用这个回收算法,当标记了可以回收的时候,会把标记的内存给回收掉。这个设计的目的估计是想更高效的使用内存(能够标记一段共享内存不用了),但是后面你会发现这个东西目前还是个摆设。mOwnsRegion 表示只有创建者才能标记这块共享内存被回收。
MemroyFile 的使用方法,就只有构造函数一个。而且默认 mAllowPurging 是 false。这个构造函数是创建共享内存的,所以 mOwnsRegion 是 true。回想下前面原理,说的 Proc A 首先要创建一块共享内存,然后再 mmap 到本进程。这里正好2个 jni:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
static jobject android_os_MemoryFile_open(JNIEnv* env, jobject clazz, jstring name, jint length)
{
const char * namestr = (name ? env->GetStringUTFChars(name, NULL) : NULL);
int result = ashmem_create_region(namestr, length);
if (name)
env->ReleaseStringUTFChars(name, namestr);
if (result < 0 ) {
jniThrowException(env, "java/io/IOException" , "ashmem_create_region failed" );
return NULL;
}
return jniCreateFileDescriptor(env, result);
}
这个 jni 很简单了,前面的 MemroyFile 传了要创建的共享内存的名字以及大小。这里主要是调用 libcutils 里面的 ashmem-dev.c 的接口去创建共享内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#define ASHMEM_DEVICE "/dev/ashmem"
int ashmem_create_region(const char *name, size_t size)
{
int fd, ret;
fd = open(ASHMEM_DEVICE, O_RDWR);
if (fd < 0 )
return fd;
if (name) {
char buf[ASHMEM_NAME_LEN];
strlcpy(buf, name, sizeof (buf));
ret = ioctl(fd, ASHMEM_SET_NAME, buf);
if (ret < 0 )
goto error;
}
ret = ioctl(fd, ASHMEM_SET_SIZE, size);
if (ret < 0 )
goto error;
return fd;
error:
close(fd);
return ret;
}
熟悉 linux 环境编程的也没啥要说的, open 打开设备。/dev/ashmem 在前面有篇文章说到,在 init.rc 里面和 /dev/binder 是系统 init 进程创建好的设备节点(虚拟机设备)。然后 ioctl 去设置名字和大小。这里就要走到 kernel 的驱动里面去了,这些后面再说。然后返回 fd。然后回到 jni 里面,通过 fd 构造出 java 的 FileDescriptor(JNIHelp.cpp):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
jobject jniCreateFileDescriptor(C_JNIEnv* env, int fd) {
JNIEnv* e = reinterpret_cast <JNIEnv*>(env);
static jmethodID ctor = e->GetMethodID(JniConstants::fileDescriptorClass, "<init>" , "()V" );
jobject fileDescriptor = (*env)->NewObject(e, JniConstants::fileDescriptorClass, ctor);
jniSetFileDescriptorOfFD(env, fileDescriptor, fd);
return fileDescriptor;
}
int jniGetFDFromFileDescriptor(C_JNIEnv* env, jobject fileDescriptor) {
JNIEnv* e = reinterpret_cast <JNIEnv*>(env);
static jfieldID fid = e->GetFieldID(JniConstants::fileDescriptorClass, "descriptor" , "I" );
return (*env)->GetIntField(e, fileDescriptor, fid);
}
void jniSetFileDescriptorOfFD(C_JNIEnv* env, jobject fileDescriptor, int value) {
JNIEnv* e = reinterpret_cast <JNIEnv*>(env);
static jfieldID fid = e->GetFieldID(JniConstants::fileDescriptorClass, "descriptor" , "I" );
(*env)->SetIntField(e, fileDescriptor, fid, value);
}
这里就能看得出,FileDescriptor 就是把 fd 封装了一下,核心还是这个 int 值啊(通过反射,用 fd 设置了一下 FileDescriptor 的 fileDescriptor 这个变量)。然后看下 mmap:
1
2
3
4
5
6
7
8
9
10
static jint android_os_MemoryFile_mmap(JNIEnv* env, jobject clazz, jobject fileDescriptor,
jint length, jint prot)
{
int fd = jniGetFDFromFileDescriptor(env, fileDescriptor);
jint result = (jint)mmap(NULL, length, prot, MAP_SHARED, fd, 0 );
if (!result)
jniThrowException(env, "java/io/IOException" , "mmap failed" );
return result;
}
这个更简单,通过 FileDescriptor 得到 fd,直接系统 mmap 。这里 mmap 也是要进到 kernel 的驱动里面的。稍微注意下, port 是 PORT_READ | PORT_WRITE 读写, flag 是 MAP_SHARED,就说明这是专为共享设置的。
Proc A 算是把共享内存创建好了也 mmap 到本进程,现在就要把 fd 倒腾给 Proc B。现在我们假设 Proc A 是 Bn 端,Proc B 是 Bp 端。然后来看看 MemroyFile 的一个接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public ParcelFileDescriptor getParcelFileDescriptor () throws IOException {
FileDescriptor fd = getFileDescriptor();
return fd != null ? new ParcelFileDescriptor(fd) : null ;
}
ParcelFileDescriptor,看名字你是不是明白了什么咧,能够 Parcelable 的 fd,这个就是让你拿来用 binder 传给 Proc B 的啊。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
ParcelFileDescriptor(FileDescriptor descriptor) {
super ();
if (descriptor == null ) {
throw new NullPointerException("descriptor must not be null" );
}
mFileDescriptor = descriptor;
mParcelDescriptor = null ;
}
public void writeToParcel (Parcel out, int flags) {
out.writeFileDescriptor(mFileDescriptor);
if ((flags&PARCELABLE_WRITE_RETURN_VALUE) != 0 && !mClosed) {
try {
close();
} catch (IOException e) {
}
}
}
public static final Parcelable.Creator<ParcelFileDescriptor> CREATOR
= new Parcelable.Creator<ParcelFileDescriptor>() {
public ParcelFileDescriptor createFromParcel (Parcel in) {
return in.readFileDescriptor();
}
public ParcelFileDescriptor[] newArray (int size) {
return new ParcelFileDescriptor[size];
}
};
ParcelFileDescriptor 其实挺简单,主要是看它的 Paracelable 接口。又是调用 Parcel 的对应接口(java jni native 放一起了,麻烦,而且下面是 2.3 的代码,4.4 的不一样了,基本上好像太能配合 MemroyFile 使用了)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
public final native void writeFileDescriptor(FileDescriptor val);
public final ParcelFileDescriptor readFileDescriptor() {
FileDescriptor fd = internalReadFileDescriptor();
return fd != null ? new ParcelFileDescriptor(fd) : null;
}
static void android_os_Parcel_writeFileDescriptor(JNIEnv* env, jobject clazz, jobject object)
{
Parcel* parcel = parcelForJavaObject(env, clazz);
if (parcel != NULL) {
const status_t err = parcel->writeDupFileDescriptor(
env->GetIntField(object, gFileDescriptorOffsets.mDescriptor));
if (err != NO_ERROR) {
jniThrowException(env, "java/lang/OutOfMemoryError" , NULL);
}
}
}
static jobject android_os_Parcel_readFileDescriptor(JNIEnv* env, jobject clazz)
{
Parcel* parcel = parcelForJavaObject(env, clazz);
if (parcel != NULL) {
int fd = parcel->readFileDescriptor();
if (fd < 0 ) return NULL;
fd = dup(fd);
if (fd < 0 ) return NULL;
jobject object = env->NewObject(
gFileDescriptorOffsets.mClass, gFileDescriptorOffsets.mConstructor);
if (object != NULL) {
env->SetIntField(object, gFileDescriptorOffsets.mDescriptor, fd);
}
return object;
}
return NULL;
}
status_t Parcel::writeDupFileDescriptor(int fd)
{
flat_binder_object obj;
obj.type = BINDER_TYPE_FD;
obj.flags = 0x7f | FLAT_BINDER_FLAG_ACCEPTS_FDS;
obj.handle = dup(fd);
obj.cookie = (void *)1 ;
return writeObject(obj, true );
}
int Parcel::readFileDescriptor() const
{
const flat_binder_object* flat = readObject(true );
if (flat) {
switch (flat->type) {
case BINDER_TYPE_FD:
return flat->handle;
}
}
return BAD_TYPE;
}
最后,是到 Parcel ,通过 flat_binder_object 来传递的。回想下前面几篇的内容,Parcel 传递 flat_binder_object 到 binder 驱动的时候,有好几种类型,当时是不是有一种 BINDER_TYPE_FD 类型被选择性的无视了,现在知道这个 FD 是专门拿来倒腾 fd 用的了吧。这里 writeDupFileDescriptor 用 dup 复制了一个 fd 封装在 flat_binder_object 里面,然后 kernel 那里倒腾后面再说。反正 binder 传到 Proc B 那边,通过 Parcelable 的 CREATEOR 调用到 readFileDescriptor 会把 flat_binder_object 读出来,然后这里的 fd 就是经过倒腾的,是 Proc B 进程能够用的了。
Proc B 拿到 fd 后就可以 mmap Proc A 创建的共享内存了(还是创建 MemroyFile):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public MemoryFile (FileDescriptor fd, int length, String mode) throws IOException {
if (fd == null ) {
throw new NullPointerException("File descriptor is null." );
}
if (!isMemoryFile(fd)) {
throw new IllegalArgumentException("Not a memory file." );
}
mLength = length;
mFD = fd;
mAddress = native_mmap(mFD, length, modeToProt(mode));
mOwnsRegion = false ;
}
这个就是 Proc A 那里省去了 open 的操作(当然,因为有现成的 fd 了)。Proc B 也把共享内存文件 mmap 到本进程后,A、B 就可以通过 MemroyFile 的 read、write 接口读写了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
public int readBytes(byte[] buffer, int srcOffset, int destOffset, int count)
throws IOException {
if (isDeactivated()) {
throw new IOException("Can't read from deactivated memory file." );
}
if (destOffset < 0 || destOffset > buffer.length || count < 0
|| count > buffer.length - destOffset
|| srcOffset < 0 || srcOffset > mLength
|| count > mLength - srcOffset) {
throw new IndexOutOfBoundsException();
}
return native_read(mFD, mAddress, buffer, srcOffset, destOffset, count, mAllowPurging);
}
public void writeBytes(byte[] buffer, int srcOffset, int destOffset, int count)
throws IOException {
if (isDeactivated()) {
throw new IOException("Can't write to deactivated memory file." );
}
if (srcOffset < 0 || srcOffset > buffer.length || count < 0
|| count > buffer.length - srcOffset
|| destOffset < 0 || destOffset > mLength
|| count > mLength - destOffset) {
throw new IndexOutOfBoundsException();
}
native_write(mFD, mAddress, buffer, srcOffset, destOffset, count, mAllowPurging);
}
static jint android_os_MemoryFile_read(JNIEnv* env, jobject clazz,
jobject fileDescriptor, jint address, jbyteArray buffer, jint srcOffset, jint destOffset,
jint count, jboolean unpinned)
{
int fd = jniGetFDFromFileDescriptor(env, fileDescriptor);
if (unpinned && ashmem_pin_region(fd, 0 , 0 ) == ASHMEM_WAS_PURGED) {
ashmem_unpin_region(fd, 0 , 0 );
jniThrowException(env, "java/io/IOException" , "ashmem region was purged" );
return -1 ;
}
env->SetByteArrayRegion(buffer, destOffset, count, (const jbyte *)address + srcOffset);
if (unpinned) {
ashmem_unpin_region(fd, 0 , 0 );
}
return count;
}
static jint android_os_MemoryFile_write(JNIEnv* env, jobject clazz,
jobject fileDescriptor, jint address, jbyteArray buffer, jint srcOffset, jint destOffset,
jint count, jboolean unpinned)
{
int fd = jniGetFDFromFileDescriptor(env, fileDescriptor);
if (unpinned && ashmem_pin_region(fd, 0 , 0 ) == ASHMEM_WAS_PURGED) {
ashmem_unpin_region(fd, 0 , 0 );
jniThrowException(env, "java/io/IOException" , "ashmem region was purged" );
return -1 ;
}
env->GetByteArrayRegion(buffer, srcOffset, count, (jbyte *)address + destOffset);
if (unpinned) {
ashmem_unpin_region(fd, 0 , 0 );
}
return count;
}
jni 里面,除去那个 unpinned 不看(mAllowPurging 默认是 false),read 和 write 很简单,就是单纯的从 mAddress(mmap 到本进程的地址)读或写数据(数据都是二进制的,至于怎么用,那是上层业务的事情了)。就算手动设置了 mAllowPurging(2.3 的源码系统里面也没主动设置的地方),ashmem_pin_region 的范围都是 0,在 kernel 驱动中, 0 代表整块区域,所以就算设置了,也暂时没起到分块使用的作用。所以这些就忽略这些东西(主要是我也不太懂 -_-||)。
是用完之后就可以调用 close 接口,先 munmap 内存映射,然后再关掉共享内存文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
public void close() {
deactivate();
if (!isClosed()) {
native_close(mFD);
}
}
public void deactivate() {
if (!isDeactivated()) {
try {
native_munmap(mAddress, mLength);
mAddress = 0 ;
} catch (IOException ex) {
Log.e(TAG, ex.toString());
}
}
}
private boolean isDeactivated() {
return mAddress == 0 ;
}
private boolean isClosed() {
return !mFD.valid();
}
static jint android_os_MemoryFile_mmap(JNIEnv* env, jobject clazz, jobject fileDescriptor,
jint length, jint prot)
{
int fd = jniGetFDFromFileDescriptor(env, fileDescriptor);
jint result = (jint)mmap(NULL, length, prot, MAP_SHARED, fd, 0 );
if (!result)
jniThrowException(env, "java/io/IOException" , "mmap failed" );
return result;
}
static void android_os_MemoryFile_munmap(JNIEnv* env, jobject clazz, jint addr, jint length)
{
int result = munmap((void *)addr, length);
if (result < 0 )
jniThrowException(env, "java/io/IOException" , "munmap failed" );
}
static void android_os_MemoryFile_close(JNIEnv* env, jobject clazz, jobject fileDescriptor)
{
int fd = jniGetFDFromFileDescriptor(env, fileDescriptor);
if (fd >= 0 ) {
jniSetFileDescriptorOfFD(env, fileDescriptor, -1 );
close(fd);
}
}
jni 里面直接就是系统调用了。open 了就要 close,mmap 了就要 munmap, 没啥好说的。前面说为什么 4.1 之后 java 的 MemroyFile 应该就没法用了呢。仔细看下上面,我贴的几个接口,是 hide 的有:
public MemoryFile(FileDescriptor fd, int length, String mode)
public ParcelFileDescriptor getParcelFileDescriptor()
这普通应用正常情况下,根本就没办法用 MemroyFile。所以后面直接把这几个 hide 接口给干掉了。所以我感觉 android 在 java 上不想普通应用直接使用 ashmem,因为很多东西是系统帮你使用了 ashmem,例如传递稍微大一点的 Bitmap。可能 android 觉得在该使用 ashmem 的地方,系统帮你弄好了,你就不要瞎操心了。
native 层接口
java 层的 MemroyFile 基本是残废的,但是 native 层的接口可是齐全的。native 层的 android 搞了2个:
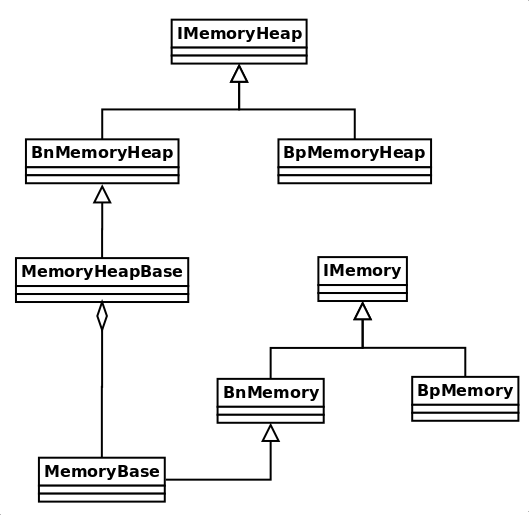
MemroyHeapBase : 这个类代表一块共享内存区域。MemroyBase : 这个是上面一块共享内存区域中的一段,就是说 native 层中是支持一段、一段的使用的(不过大多时候是把上面一块就当成一块用 -_-||)。IMemory : binder 接口。
流程也是和原理一样的,先是 Proc A 创建一块共享内存区域(创建一个 MemroyHeapBase 对象):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
MemoryHeapBase::MemoryHeapBase(size_t size, uint32_t flags, char const * name)
: mFD(-1 ), mSize(0 ), mBase(MAP_FAILED), mFlags(flags),
mDevice(0 ), mNeedUnmap(false ), mOffset(0 )
{
const size_t pagesize = getpagesize();
size = ((size + pagesize-1 ) & ~(pagesize-1 ));
int fd = ashmem_create_region(name == NULL ? "MemoryHeapBase" : name, size);
ALOGE_IF(fd<0 , "error creating ashmem region: %s" , strerror(errno));
if (fd >= 0 ) {
if (mapfd(fd, size) == NO_ERROR) {
if (flags & READ_ONLY) {
ashmem_set_prot_region(fd, PROT_READ);
}
}
}
}
底层的接口和 jni 的的一样的,创建也是调用 libcutils 的 ashmem-dev.c 相关接口。然后 mapfd 是 mmap 内存到本进程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
status_t MemoryHeapBase::mapfd(int fd, size_t size, uint32_t offset)
{
if (size == 0 ) {
#ifdef HAVE_ANDROID_OS
pmem_region reg;
int err = ioctl(fd, PMEM_GET_TOTAL_SIZE, ®);
if (err == 0 )
size = reg.len;
#endif
if (size == 0 ) {
struct stat sb;
if (fstat(fd, &sb) == 0 )
size = sb.st_size;
}
}
if ((mFlags & DONT_MAP_LOCALLY) == 0 ) {
void * base = (uint8_t*)mmap(0 , size,
PROT_READ|PROT_WRITE, MAP_SHARED, fd, offset);
if (base == MAP_FAILED) {
ALOGE("mmap(fd=%d, size=%u) failed (%s)" ,
fd, uint32_t(size), strerror(errno));
close(fd);
return -errno;
}
mBase = base;
mNeedUnmap = true ;
} else {
mBase = 0 ;
mNeedUnmap = false ;
}
mFD = fd;
mSize = size;
mOffset = offset;
return NO_ERROR;
}
这个函数正常情况下,排除那几个特殊标志,就是调用了系统接口 mmap,然后把 fd,映射得到的地址,大小,偏移保存了一下。这下 Proc A 的共享内存区域就创建好了。不过前面说了, native 层的接口,真正使用的是 MemroyBase,这个可以从 MemroyHeapBase 中指定一段区域来使用,这里我们考虑把 MemroyHeapBase 当成一整块来使用。MemroyXx 都实现了 binder 相关的接口(忘记了的,回去看第一篇原理,其实封装搞多了我也是醉了):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
class BnMemoryHeap : public BnInterface<IMemoryHeap>
{
public :
virtual status_t onTransact(
uint32_t code,
const Parcel& data,
Parcel* reply,
uint32_t flags = 0 );
BnMemoryHeap();
protected :
virtual ~BnMemoryHeap();
};
class MemoryHeapBase : public virtual BnMemoryHeap
{
... ...
}
class MemoryBase : public BnMemory
{
public :
MemoryBase(const sp<IMemoryHeap>& heap, ssize_t offset, size_t size);
virtual ~MemoryBase();
virtual sp<IMemoryHeap> getMemory(ssize_t* offset, size_t* size) const ;
protected :
size_t getSize() const { return mSize; }
ssize_t getOffset() const { return mOffset; }
const sp<IMemoryHeap>& getHeap() const { return mHeap; }
private :
size_t mSize;
ssize_t mOffset;
sp<IMemoryHeap> mHeap;
};
MemoryBase::MemoryBase(const sp<IMemoryHeap>& heap,
ssize_t offset, size_t size)
: mSize(size), mOffset(offset), mHeap(heap)
{
}
所以说,举个例子说,Proc A 中创建了一个 2048 byte 的 MemroyHeapBase,要整块一起使用,应该是下面这样写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class ProcA : public BinderService<ProcA>,
public BnProcA
{
public :
static char const * getServiceName() {
return "ProcA" ;
}
ProcA();
~ProcA();
private :
virtual status_t onTransact(uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags);
virtual sp<IMemory> getMemory();
sp<MemoryBase> mMemory;
};
ProcA::K7Service()
: BnK7() {
sp<MemoryHeapBase> heap = new MemoryHeapBase(2048 , 0 , "K7Service" );
mMemory = new MemoryBase(heap, 0 , 2048 );
}
那么接下来 Proc A 只要把 fd 倒腾给 Proc B 就行了。不过这里 fd 是封装在 MemroyHeapBase 里面的,真正使用的又是 MemroyBase,而且又实现了 binder 接口,当然得一层层转。首先得把 MemroyBase 传给 Proc B,MemroyBase 的 binder 接口是 IMemroy(IBinder),把这个通过 binder 扔给 Proc B 先。我们假设在 Proc A 的 binder 接口中有一个教 getMemroy 的接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class BpProcA : public BpInterface<IProcA>
{
public :
virtual sp<IMemory> getMemory() {
Parcel data, reply;
data.writeInterfaceToken(IProcA::getInterfaceDescriptor());
remote()->transact(BnProcA::GET_MEMORY, data, &reply);
sp<IMemory> memory = interface_cast<IMemory>(reply.readStrongBinder());
return memory;
}
}
status_t BnProcA::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch (code) {
case GET_MEMORY: {
CHECK_INTERFACE(IProcA, data, reply);
sp<IMemory> memory = getMemory();
reply->writeStrongBinder(memory->asBinder());
} break ;
default :
return BBinder::onTransact(code, data, reply, flags);
}
return NO_ERROR;
}
sp<IMemory> K7Service::getMemory() {
return mMemory;
}
Parcel 的 readStrongBinder 和 writeStrongBinder 前面说过了,Parcel 的 flat_binder_object 专门用来传递 binder 对象的。IMemroy 传到 Proc B 后,来看看 IMemroy 有哪些接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class IMemory : public IInterface
{
public :
DECLARE_META_INTERFACE(Memory);
virtual sp<IMemoryHeap> getMemory(ssize_t* offset=0 , size_t* size=0 ) const = 0 ;
void * fastPointer(const sp<IBinder>& heap, ssize_t offset) const ;
void * pointer() const ;
size_t size() const ;
ssize_t offset() const ;
};
class BnMemory : public BnInterface<IMemory>
{
public :
virtual status_t onTransact(
uint32_t code,
const Parcel& data,
Parcel* reply,
uint32_t flags = 0 );
BnMemory();
protected :
virtual ~BnMemory();
};
void * IMemory::pointer() const {
ssize_t offset;
sp<IMemoryHeap> heap = getMemory(&offset);
void * const base = heap!=0 ? heap->base() : MAP_FAILED;
if (base == MAP_FAILED)
return 0 ;
return static_cast <char *>(base) + offset;
}
size_t IMemory::size() const {
size_t size;
getMemory(NULL, &size);
return size;
}
ssize_t IMemory::offset() const {
ssize_t offset;
getMemory(&offset);
return offset;
}
基本上可以看得出, pointer() 是返回共享内存的地址,这个地址是已经映射到 Proc B 中了的,就是可以直接读、写了的。然后 size() 和 offset() 分别是返回大小和偏移(例子中是 2048 和 0)。
然后,它们都调用了一个比较关键的函数叫 getMemroy:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
sp<IMemoryHeap> MemoryBase::getMemory(ssize_t* offset, size_t* size) const
{
if (offset) *offset = mOffset;
if (size) *size = mSize;
return mHeap;
}
sp<IMemoryHeap> BpMemory::getMemory(ssize_t* offset, size_t* size) const
{
if (mHeap == 0 ) {
Parcel data, reply;
data.writeInterfaceToken(IMemory::getInterfaceDescriptor());
if (remote()->transact(GET_MEMORY, data, &reply) == NO_ERROR) {
sp<IBinder> heap = reply.readStrongBinder();
ssize_t o = reply.readInt32();
size_t s = reply.readInt32();
if (heap != 0 ) {
mHeap = interface_cast<IMemoryHeap>(heap);
if (mHeap != 0 ) {
mOffset = o;
mSize = s;
}
}
}
}
if (offset) *offset = mOffset;
if (size) *size = mSize;
return mHeap;
}
status_t BnMemory::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch (code) {
case GET_MEMORY: {
CHECK_INTERFACE(IMemory, data, reply);
ssize_t offset;
size_t size;
reply->writeStrongBinder( getMemory(&offset, &size)->asBinder() );
reply->writeInt32(offset);
reply->writeInt32(size);
return NO_ERROR;
} break ;
default :
return BBinder::onTransact(code, data, reply, flags);
}
}
这个叫 getMemroy 的最后其实是把 MemoryBase 用的 MemoryHeapBase 的 binder 接口(IMemroyHeap)传了过来(前面说了要一层层转的吧)。然后我们就得来看看 IMemroyHeap 的接口了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
int MemoryHeapBase::getHeapID() const {
return mFD;
}
class IMemoryHeap : public IInterface
{
public :
DECLARE_META_INTERFACE(MemoryHeap);
enum {
READ_ONLY = 0x00000001
};
virtual int getHeapID() const = 0 ;
virtual void * getBase() const = 0 ;
virtual size_t getSize() const = 0 ;
virtual uint32_t getFlags() const = 0 ;
virtual uint32_t getOffset() const = 0 ;
int32_t heapID() const { return getHeapID(); }
void * base() const { return getBase(); }
size_t virtualSize() const { return getSize(); }
};
class BnMemoryHeap : public BnInterface<IMemoryHeap>
{
public :
virtual status_t onTransact(
uint32_t code,
const Parcel& data,
Parcel* reply,
uint32_t flags = 0 );
BnMemoryHeap();
protected :
virtual ~BnMemoryHeap();
};
int BpMemoryHeap::getHeapID() const {
assertMapped();
return mHeapId;
}
void * BpMemoryHeap::getBase() const {
assertMapped();
return mBase;
}
size_t BpMemoryHeap::getSize() const {
assertMapped();
return mSize;
}
uint32_t BpMemoryHeap::getFlags() const {
assertMapped();
return mFlags;
}
uint32_t BpMemoryHeap::getOffset() const {
assertMapped();
return mOffset;
}
status_t BnMemoryHeap::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch (code) {
case HEAP_ID: {
CHECK_INTERFACE(IMemoryHeap, data, reply);
reply->writeFileDescriptor(getHeapID());
reply->writeInt32(getSize());
reply->writeInt32(getFlags());
reply->writeInt32(getOffset());
return NO_ERROR;
} break ;
default :
return BBinder::onTransact(code, data, reply, flags);
}
}
上面 IMemory 那里获取到 IMemroyHeap 后,调用的是 base(), 这个最后是调用 getBaes() 的。但是这几个 Bp 端的接口实现,无一例外,全都调用了另一个关键的函数(又是关键的 -_-||):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
void BpMemoryHeap::assertMapped() const
{
if (mHeapId == -1 ) {
sp<IBinder> binder(const_cast <BpMemoryHeap*>(this )->asBinder());
sp<BpMemoryHeap> heap(static_cast <BpMemoryHeap*>(find_heap(binder).get()));
heap->assertReallyMapped();
if (heap->mBase != MAP_FAILED) {
Mutex::Autolock _l(mLock);
if (mHeapId == -1 ) {
mBase = heap->mBase;
mSize = heap->mSize;
mOffset = heap->mOffset;
android_atomic_write( dup( heap->mHeapId ), &mHeapId );
}
} else {
free_heap(binder);
}
}
}
void BpMemoryHeap::assertReallyMapped() const
{
if (mHeapId == -1 ) {
Parcel data, reply;
data.writeInterfaceToken(IMemoryHeap::getInterfaceDescriptor());
status_t err = remote()->transact(HEAP_ID, data, &reply);
int parcel_fd = reply.readFileDescriptor();
ssize_t size = reply.readInt32();
uint32_t flags = reply.readInt32();
uint32_t offset = reply.readInt32();
ALOGE_IF(err, "binder=%p transaction failed fd=%d, size=%ld, err=%d (%s)" ,
asBinder().get(), parcel_fd, size, err, strerror(-err));
int fd = dup( parcel_fd );
ALOGE_IF(fd==-1 , "cannot dup fd=%d, size=%ld, err=%d (%s)" ,
parcel_fd, size, err, strerror(errno));
int access = PROT_READ;
if (!(flags & READ_ONLY)) {
access |= PROT_WRITE;
}
Mutex::Autolock _l(mLock);
if (mHeapId == -1 ) {
mRealHeap = true ;
mBase = mmap(0 , size, access, MAP_SHARED, fd, offset);
if (mBase == MAP_FAILED) {
ALOGE("cannot map BpMemoryHeap (binder=%p), size=%ld, fd=%d (%s)" ,
asBinder().get(), size, fd, strerror(errno));
close(fd);
} else {
mSize = size;
mFlags = flags;
mOffset = offset;
android_atomic_write(fd, &mHeapId);
}
}
}
}
这里 Proc B 是要用到共享内存才会去 mmap 的。assertMapped()、assertReallyMapped() 这2个名字还真直白。 mHeapId 就是 Proc A 倒腾给 Proc B 的 fd,如果为 -1 表示 Proc B 还没 mmap 过,所以进入 assert(Really)Mapped() 进行 mmap 。assertMapped() 那里有个 find_heap 的东西,看起来挺多余的,直接调用自己的函数有那么费劲么,后面看了下注释好像是拿来调试用的,那就不用管它了。然后 assertReallyMapped 就和 java 层的差不多了,先是发一个 HEAP_ID 给 MemoryHeapBase 的 Bn 让它把 Proc A 那边的 fd 通过 Parcel 的 writeFileDescriptor 倒腾
native 层的接口返回的直接是地址,读写比 java 层的灵活很多。然后 native 的 close、munmap 都是在析够函数中进行的,可以说配合 android 的智能指针(其实我挺讨厌这玩意),可以说使用无脑(用 sp,初始化的时候 new 出来,在析构函数里置为 NULL 就行了)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
MemoryHeapBase::~MemoryHeapBase()
{
dispose();
}
void MemoryHeapBase::dispose()
{
int fd = android_atomic_or(-1 , &mFD);
if (fd >= 0 ) {
if (mNeedUnmap) {
munmap(mBase, mSize);
}
mBase = 0 ;
mSize = 0 ;
close(fd);
}
}
BpMemoryHeap::~BpMemoryHeap() {
if (mHeapId != -1 ) {
close(mHeapId);
if (mRealHeap) {
if (mBase != MAP_FAILED) {
sp<IBinder> binder = const_cast <BpMemoryHeap*>(this )->asBinder();
if (VERBOSE) {
ALOGD("UNMAPPING binder=%p, heap=%p, size=%d, fd=%d" ,
binder.get(), this , mSize, mHeapId);
CallStack stack (LOG_TAG);
}
munmap(mBase, mSize);
}
} else {
sp<IBinder> binder = const_cast <BpMemoryHeap*>(this )->asBinder();
free_heap(binder);
}
}
}
又是 MemoryHeapBase、MemoryBase、IMemoryBase、IMemory 是不是有点头晕咧,主要是 android 在 native 层搞了2个东西,加那一堆 binder 接口,这还没 java 层简洁(虽然 java 层的被废掉了 -_-||)。最后来张图吧:
kernel 驱动
上面把应用层的接口说往了,下面就要讲 kernel 里面的驱动了。最开始的时候说了, ashmem 是基于 linux 的 tmpfs 实现的,所以最好要有点这方面的知识,不过目前我还是不太清楚 tmpfs 相关的接口用法 -_-||,等以后找点书来看补补吧。
前面那些接口最后面就是调用到 libcutils 的 ashmem-dev.c 中的那些接口,那些接口最后都是 open 或是 ioctl 的系统调用,这些最后都是进入到 kernel 的 ashmem 驱动当中。
我们先来看下 ashmem 驱动加载初始化的时候:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
struct ashmem_area {
char name[ASHMEM_FULL_NAME_LEN];
struct list_head unpinned_list;
struct file *file;
size_t size;
unsigned long prot_mask;
};
static struct kmem_cache *ashmem_area_cachep __read_mostly;
static struct kmem_cache *ashmem_range_cachep __read_mostly;
static int __init ashmem_init(void )
{
int ret;
ashmem_area_cachep = kmem_cache_create("ashmem_area_cache" ,
sizeof (struct ashmem_area),
0 , 0 , NULL);
if (unlikely(!ashmem_area_cachep)) {
printk(KERN_ERR "ashmem: failed to create slab cache\n" );
return -ENOMEM;
}
ashmem_range_cachep = kmem_cache_create("ashmem_range_cache" ,
sizeof (struct ashmem_range),
0 , 0 , NULL);
if (unlikely(!ashmem_range_cachep)) {
printk(KERN_ERR "ashmem: failed to create slab cache\n" );
return -ENOMEM;
}
ret = misc_register(&ashmem_misc);
if (unlikely(ret)) {
printk(KERN_ERR "ashmem: failed to register misc device!\n" );
return ret;
}
register_shrinker(&ashmem_shrinker);
printk(KERN_INFO "ashmem: initialized\n" );
return 0 ;
}
static void __exit ashmem_exit(void )
{
int ret;
unregister_shrinker(&ashmem_shrinker);
ret = misc_deregister(&ashmem_misc);
if (unlikely(ret))
printk(KERN_ERR "ashmem: failed to unregister misc device!\n" );
kmem_cache_destroy(ashmem_range_cachep);
kmem_cache_destroy(ashmem_area_cachep);
printk(KERN_INFO "ashmem: unloaded\n" );
}
module_init(ashmem_init);
module_exit(ashmem_exit);
init 和 exit 函数是 kernel 第一次加载 ashmem 模块的时候调用的,一般做一些驱动初始化或是申请资源相关的操作。这里首先在 kernel 的后备高速缓存区开辟的一段空间,用来申请 struct ashmem_area 这个驱动相关的结构体的存储空间。这个后备高速缓存据说是应用于反复的多次分配的情况,因为 ashmem 本身就是出于性能考虑设计的,所以选择使用这个吧,能够加快分配内存的速度(注意这里只是分配驱动保存一些状态的数据结构,不是共享内存本身)。这个后备高速缓存好像又叫 slab 分配器,好像是 kernel 里面挺快的一个东西 -_-|| 。
然后后面那个和 pin/unpin 还有内存回收算法相关的,我现在不打算去分析,因为第一,这个东西前面说过了,现在基本上没用;第二,最主要的是我也不是很清楚这些玩意 -_-||。再后注册驱动操作相关函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
static struct file_operations ashmem_fops = {
.owner = THIS_MODULE,
.open = ashmem_open,
.release = ashmem_release,
.read = ashmem_read,
.llseek = ashmem_llseek,
.mmap = ashmem_mmap,
.unlocked_ioctl = ashmem_ioctl,
.compat_ioctl = ashmem_ioctl,
};
static struct miscdevice ashmem_misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = "ashmem" ,
.fops = &ashmem_fops,
};
稍微接触过点 linux 驱动的都应该知道,这个 file_operations 就是 linux 文件设备驱动(linux 上所有设置都是文件)的操作函数。例如说上层应用对本设备调用 open 对应的驱动函数就是 .open 对应的,然后依此类推:
mmap --> .mmap(ashmem_mapp)
ioctl --> .unlocked_ioctl(ashmem_ioctl)
.compat_ioctl(ashmem_ioctl)
close --> .release(ashmem_release)
read --> .read(ashmem_read)
seek --> llseek(ashmem_llseek)
file_operations 的操作函数不止这几个,没实现的就不支持对应的操作,上层调用接口,会返回错误值。以前 2.3 的 ashmem 不支持 read 和 seek 的,4.x 的开始支持啦,不过这里只关注另外几个重要的。
首先是 Proc A 调用 open 创建共享内存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
static int ashmem_open(struct inode *inode, struct file *file)
{
struct ashmem_area *asma;
int ret;
ret = generic_file_open(inode, file);
if (unlikely(ret))
return ret;
asma = kmem_cache_zalloc(ashmem_area_cachep, GFP_KERNEL);
if (unlikely(!asma))
return -ENOMEM;
INIT_LIST_HEAD(&asma->unpinned_list);
memcpy (asma->name, ASHMEM_NAME_PREFIX, ASHMEM_NAME_PREFIX_LEN);
asma->prot_mask = PROT_MASK;
file->private_data = asma;
return 0 ;
}
这个函数 kernel 传递过来2个参数,第一个 inode 是文件设备节点,前面说了一个真实的文件只有一个设备节点。后面那个是文件指针,但是一个文件可以打开多次,每打开一次就有一个文件指针对应。那个 generic_file_open kernel 的接口,具体目前我也不是很清楚,反正就理解为调用 kernel 接口打开指定的文件设备吧 -_-||。然后利用 init 中开辟的高速缓存创建驱动的私有驱动数据,看上面, ashmem 的私有结构挺简单的,基本上就是名字、大小、打开的文件指针和端口标志(那个 unpin 的 list 咱们无视)。然后这里强制把名字的前缀设置为:
#define ASHMEM_NAME_PREFIX "dev/ashmem/"
注意这里只是设置前缀而已,后面有 set_name 的 ioctl 接口的,这个接口是把用户设置的名字加在后面而已,基本上名字就是: “dev/shmem/xx”,这个名字感觉除了在 cat /proc/pid/maps 的时候显示一下以外就没啥别的用处了(而且好多应用还不设置)。
然后就是把在高速缓存区创建的 ashmem_area 保持在 file->private_data 这个字段中。这是很多驱动的通用做法,把私有的数据结构保持在这个字段,在后面的 ioctl 里面能取出来用。
然后 Proc A 就该调用 mmap 了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
static int ashmem_mmap(struct file *file, struct vm_area_struct *vma)
{
struct ashmem_area *asma = file->private_data;
int ret = 0 ;
mutex_lock(&ashmem_mutex);
if (unlikely(!asma->size)) {
ret = -EINVAL;
goto out;
}
if (unlikely((vma->vm_flags & ~calc_vm_prot_bits(asma->prot_mask)) &
calc_vm_prot_bits(PROT_MASK))) {
ret = -EPERM;
goto out;
}
vma->vm_flags &= ~calc_vm_may_flags(~asma->prot_mask);
if (!asma->file) {
char *name = ASHMEM_NAME_DEF;
struct file *vmfile;
if (asma->name[ASHMEM_NAME_PREFIX_LEN] != '\0' )
name = asma->name;
vmfile = shmem_file_setup(name, asma->size, vma->vm_flags);
if (unlikely(IS_ERR(vmfile))) {
ret = PTR_ERR(vmfile);
goto out;
}
asma->file = vmfile;
}
get_file(asma->file);
if (vma->vm_flags & VM_SHARED)
shmem_set_file(vma, asma->file);
else {
if (vma->vm_file)
fput(vma->vm_file);
vma->vm_file = asma->file;
}
vma->vm_flags |= VM_CAN_NONLINEAR;
out:
mutex_unlock(&ashmem_mutex);
return ret;
}
static long ashmem_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
struct ashmem_area *asma = file->private_data;
long ret = -ENOTTY;
switch (cmd) {
case ASHMEM_SET_NAME:
ret = set_name(asma, (void __user *) arg);
break ;
case ASHMEM_GET_NAME:
ret = get_name(asma, (void __user *) arg);
break ;
case ASHMEM_SET_SIZE:
ret = -EINVAL;
if (!asma->file) {
ret = 0 ;
asma->size = (size_t) arg;
}
break ;
case ASHMEM_GET_SIZE:
ret = asma->size;
break ;
case ASHMEM_SET_PROT_MASK:
ret = set_prot_mask(asma, arg);
break ;
case ASHMEM_GET_PROT_MASK:
ret = asma->prot_mask;
break ;
case ASHMEM_PIN:
case ASHMEM_UNPIN:
case ASHMEM_GET_PIN_STATUS:
ret = ashmem_pin_unpin(asma, cmd, (void __user *) arg);
break ;
case ASHMEM_PURGE_ALL_CACHES:
ret = -EPERM;
if (capable(CAP_SYS_ADMIN)) {
struct shrink_control sc = {
.gfp_mask = GFP_KERNEL,
.nr_to_scan = 0 ,
};
ret = ashmem_shrink(&ashmem_shrinker, &sc);
sc.nr_to_scan = ret;
ashmem_shrink(&ashmem_shrinker, &sc);
}
break ;
}
return ret;
}
mmap 一开始要在调用前需要调用 ioctl SET_SIZE 设置这片共享内存区域的大小。回去前面看下 ashmem_create_region 是不是在 open 之后,调用了 ioctl 去设置大小。所以我把 ioctl 那部分也贴出来了,SET_SIZE 其实很简单,就是把 asm->size 设置了一下。但是我觉得有点奇怪,上层调用 mmap 的时候也传了 size 了(size 和 调用 ioctl 的一样),那为什么不像 binder 的那样使用 vma 中的 size 。这点我就暂时无法理解了(对 kernel 相关的知识不太了解)。
然后后面的就能更难理解了,调用 shmem_file_setup 据说好像是 kernel 的 tmpfs 的接口,然后从参数看,姑且就认为在 tmpfs 上创建了一个名字为 name,大小为 asm->size 的文件,用于共享内存。后面那个 get_file 也不知道用处是什么(主要是没百度到)。然后 flags,前面 mmap 的时候,都设置了 MAP_SHARED,这里 shmem_set_file 就说是 android 在 kernel 中自己加的接口,我就更不知道是干啥用的了。不过看名字,加上参数,好像是激活刚刚创建的文件吧。然后就完了 -_-||。
其实 ashmem 的 kernel 驱动,这里就只能大致讲个原理,具体的因为不太懂 kernel 文件系统、I/O 相关的东西,没办法继续分析下去了,等以后再说吧。
然后就应该到 Proc A 把 fd 倒腾给 Proc B 了,这里倒腾要借助 binder 的驱动。还记得 Parcel 的 flat_binder_object 么,binder 的驱动专门处理这个东西的,那么就要去看 Parcel 的 flat_binder_object 在 binder 里面怎么倒腾的了。前面说 BINDER_TYPE_FD 这个类型就是专门到来倒腾 fd 的,这个在 binder_transaction 中(忘记流程了的,回去复习下前面几篇):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply)
{
struct binder_transaction *t;
struct binder_work *tcomplete;
size_t *offp, *off_end;
struct binder_proc *target_proc;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct list_head *target_list;
wait_queue_head_t *target_wait;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
uint32_t return_error;
... ...
offp = (size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof (void *)));
if (copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"data ptr\n" , proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
if (copy_from_user(offp, tr->data.ptr.offsets, tr->offsets_size)) {
binder_user_error("binder: %d:%d got transaction with invalid "
"offsets ptr\n" , proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
if (!IS_ALIGNED(tr->offsets_size, sizeof (size_t))) {
binder_user_error("binder: %d:%d got transaction with "
"invalid offsets size, %zd\n" ,
proc->pid, thread->pid, tr->offsets_size);
return_error = BR_FAILED_REPLY;
goto err_bad_offset;
}
off_end = (void *)offp + tr->offsets_size;
for (; offp < off_end; offp++) {
struct flat_binder_object *fp;
if (*offp > t->buffer->data_size - sizeof (*fp) ||
t->buffer->data_size < sizeof (*fp) ||
!IS_ALIGNED(*offp, sizeof (void *))) {
binder_user_error("binder: %d:%d got transaction with "
"invalid offset, %zd\n" ,
proc->pid, thread->pid, *offp);
return_error = BR_FAILED_REPLY;
goto err_bad_offset;
}
fp = (struct flat_binder_object *)(t->buffer->data + *offp);
switch (fp->type) {
... ...
case BINDER_TYPE_FD: {
int target_fd;
struct file *file;
if (reply) {
if (!(in_reply_to->flags & TF_ACCEPT_FDS)) {
binder_user_error("binder: %d:%d got reply with fd, %ld, but target does not allow fds\n" ,
proc->pid, thread->pid, fp->handle);
return_error = BR_FAILED_REPLY;
goto err_fd_not_allowed;
}
} else if (!target_node->accept_fds) {
binder_user_error("binder: %d:%d got transaction with fd, %ld, but target does not allow fds\n" ,
proc->pid, thread->pid, fp->handle);
return_error = BR_FAILED_REPLY;
goto err_fd_not_allowed;
}
file = fget(fp->handle);
if (file == NULL) {
binder_user_error("binder: %d:%d got transaction with invalid fd, %ld\n" ,
proc->pid, thread->pid, fp->handle);
return_error = BR_FAILED_REPLY;
goto err_fget_failed;
}
target_fd = task_get_unused_fd_flags(target_proc, O_CLOEXEC);
if (target_fd < 0 ) {
fput(file);
return_error = BR_FAILED_REPLY;
goto err_get_unused_fd_failed;
}
task_fd_install(target_proc, target_fd, file);
binder_debug(BINDER_DEBUG_TRANSACTION,
" fd %ld -> %d\n" , fp->handle, target_fd);
fp->handle = target_fd;
} break ;
default :
binder_user_error("binder: %d:%d got transactio"
"n with invalid object type, %lx\n" ,
proc->pid, thread->pid, fp->type);
return_error = BR_FAILED_REPLY;
goto err_bad_object_type;
}
}
... ...
}
这里倒腾的主要是另外2个函数:
task_get_unused_fd_flags: 在目标进程中找到空闲的 fdtask_fd_install: 在目标进程空闲的 fd 中安装 Proc A 中打开的文件指针
我看来看下这2个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
int task_get_unused_fd_flags(struct binder_proc *proc, int flags)
{
struct files_struct *files = proc->files;
int fd, error;
struct fdtable *fdt;
unsigned long rlim_cur;
unsigned long irqs;
if (files == NULL)
return -ESRCH;
error = -EMFILE;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files);
fd = find_next_zero_bit(fdt->open_fds->fds_bits, fdt->max_fds,
files->next_fd);
rlim_cur = 0 ;
if (lock_task_sighand(proc->tsk, &irqs)) {
rlim_cur = proc->tsk->signal->rlim[RLIMIT_NOFILE].rlim_cur;
unlock_task_sighand(proc->tsk, &irqs);
}
if (fd >= rlim_cur)
goto out;
error = expand_files(files, fd);
if (error < 0 )
goto out;
if (error) {
error = -EMFILE;
goto repeat;
}
FD_SET(fd, fdt->open_fds);
if (flags & O_CLOEXEC)
FD_SET(fd, fdt->close_on_exec);
else
FD_CLR(fd, fdt->close_on_exec);
files->next_fd = fd + 1 ;
#if 1
if (fdt->fd[fd] != NULL) {
printk(KERN_WARNING "get_unused_fd: slot %d not NULL!\n" , fd);
fdt->fd[fd] = NULL;
}
#endif
error = fd;
out:
spin_unlock(&files->file_lock);
return error;
}
static void task_fd_install(
struct binder_proc *proc, unsigned int fd, struct file *file)
{
struct files_struct *files = proc->files;
struct fdtable *fdt;
if (files == NULL)
return ;
spin_lock(&files->file_lock);
fdt = files_fdtable(files);
BUG_ON(fdt->fd[fd] != NULL);
rcu_assign_pointer(fdt->fd[fd], file);
spin_unlock(&files->file_lock);
}
这2个函数现在的我完全无法解释啥,看注释好像是从 kernel 的文件 I/O 中抄过来的,我又醉了 -_-|| 。反正就知道经过这2个函数的倒腾后,Proc A 的 fd 就能扔给 Proc B 用了。然后 Proc B 就能那这个 fd 去 mmap Proc A 在 tmpfs 上创建的共享内存文件了。然后 mmap 到地址后,就能读、写了。
呃,最后看看 close 的操作吧(这个相对能理解点):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
static int ashmem_release(struct inode *ignored, struct file *file)
{
struct ashmem_area *asma = file->private_data;
struct ashmem_range *range, *next;
mutex_lock(&ashmem_mutex);
list_for_each_entry_safe(range, next, &asma->unpinned_list, unpinned)
range_del(range);
mutex_unlock(&ashmem_mutex);
if (asma->file)
fput(asma->file);
kmem_cache_free(ashmem_area_cachep, asma);
return 0 ;
}
抛去 pin/unping 的不看,这里就是把 open 里面从高速缓存中申请的 ashmem_area 给释放掉了。
例子
上面说了那么多,咋来点例子来看下 framework 中是怎么使用 ashmem 的。前面说 java 层 android 不希望开发者自己倒腾 ashmem,这里我们拿用 Parcel 传递 Bitmap 为例子。图片算是比较大型的资源了,大的图片也很占内存,当你使用 Parcel 传递 Bitmap android 自动帮我们使用 ashmem 了,因为 Bitmap 是 Parcelable 的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public static final Parcelable.Creator<Bitmap> CREATOR
= new Parcelable.Creator<Bitmap>() {
/**
* Rebuilds a bitmap previously stored with writeToParcel().
*
* @param p Parcel object to read the bitmap from
* @return a new bitmap created from the data in the parcel
*/
public Bitmap createFromParcel (Parcel p) {
Bitmap bm = nativeCreateFromParcel(p);
if (bm == null ) {
throw new RuntimeException("Failed to unparcel Bitmap" );
}
return bm;
}
public Bitmap[] newArray (int size) {
return new Bitmap[size];
}
};
public int describeContents () {
return 0 ;
}
public void writeToParcel (Parcel p, int flags) {
checkRecycled("Can't parcel a recycled bitmap" );
if (!nativeWriteToParcel(mNativeBitmap, mIsMutable, mDensity, p)) {
throw new RuntimeException("native writeToParcel failed" );
}
}
挂 jni 的马甲咧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
static jboolean Bitmap_writeToParcel(JNIEnv* env, jobject,
const SkBitmap* bitmap,
jboolean isMutable, jint density,
jobject parcel) {
if (parcel == NULL) {
SkDebugf("------- writeToParcel null parcel\n" );
return false ;
}
android::Parcel* p = android::parcelForJavaObject(env, parcel);
p->writeInt32(isMutable);
p->writeInt32(bitmap->config());
p->writeInt32(bitmap->width());
p->writeInt32(bitmap->height());
p->writeInt32(bitmap->rowBytes());
p->writeInt32(density);
if (bitmap->getConfig() == SkBitmap::kIndex8_Config) {
SkColorTable* ctable = bitmap->getColorTable();
if (ctable != NULL) {
int count = ctable->count();
p->writeInt32(count);
memcpy (p->writeInplace(count * sizeof (SkPMColor)),
ctable->lockColors(), count * sizeof (SkPMColor));
ctable->unlockColors(false );
} else {
p->writeInt32(0 );
}
}
size_t size = bitmap->getSize();
android::Parcel::WritableBlob blob;
android::status_t status = p->writeBlob(size, &blob);
if (status) {
doThrowRE(env, "Could not write bitmap to parcel blob." );
return false ;
}
bitmap->lockPixels();
const void * pSrc = bitmap->getPixels();
if (pSrc == NULL) {
memset (blob.data(), 0 , size);
} else {
memcpy (blob.data(), pSrc, size);
}
bitmap->unlockPixels();
blob.release();
return true ;
}
这个函数主要是调用 Parcel 的 writeBlob 创建 ashmem,并初始化 Blob。然后把 bitmap 的 pixels 数据 copy 到 ashmem 中,注意 copy 完之后 Proc A 就不再需要对 ashmem 进行操作了,所以后面就 munmap(下面 Blob 的代码可以看到 release 只是 munmap 而已,没 close,这里还不能 close 要等 Proc B 读完才能 close)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
class Blob {
public :
Blob();
~Blob();
void release();
inline size_t size() const { return mSize; }
protected :
void init(bool mapped, void * data, size_t size);
void clear();
bool mMapped;
void * mData;
size_t mSize;
};
Parcel::Blob::Blob() :
mMapped(false ), mData(NULL), mSize(0 ) {
}
Parcel::Blob::~Blob() {
release();
}
void Parcel::Blob::release() {
if (mMapped && mData) {
::munmap(mData, mSize);
}
clear();
}
void Parcel::Blob::init(bool mapped, void * data, size_t size) {
mMapped = mapped;
mData = data;
mSize = size;
}
void Parcel::Blob::clear() {
mMapped = false ;
mData = NULL;
mSize = 0 ;
}
十分简单,然后再来看 Parcel Blob 相关操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
status_t Parcel::writeBlob(size_t len, WritableBlob* outBlob)
{
status_t status;
if (!mAllowFds || len <= IN_PLACE_BLOB_LIMIT) {
ALOGV("writeBlob: write in place" );
status = writeInt32(0 );
if (status) return status;
void * ptr = writeInplace(len);
if (!ptr) return NO_MEMORY;
outBlob->init(false , ptr, len);
return NO_ERROR;
}
ALOGV("writeBlob: write to ashmem" );
int fd = ashmem_create_region("Parcel Blob" , len);
if (fd < 0 ) return NO_MEMORY;
int result = ashmem_set_prot_region(fd, PROT_READ | PROT_WRITE);
if (result < 0 ) {
status = result;
} else {
void * ptr = ::mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0 );
if (ptr == MAP_FAILED) {
status = -errno;
} else {
result = ashmem_set_prot_region(fd, PROT_READ);
if (result < 0 ) {
status = result;
} else {
status = writeInt32(1 );
if (!status) {
status = writeFileDescriptor(fd, true );
if (!status) {
outBlob->init(true , ptr, len);
return NO_ERROR;
}
}
}
}
::munmap(ptr, len);
}
::close(fd);
return status;
}
然后回去看 Bitmap createFromParcel 接口的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
static jobject Bitmap_createFromParcel(JNIEnv* env, jobject, jobject parcel) {
if (parcel == NULL) {
SkDebugf("-------- unparcel parcel is NULL\n" );
return NULL;
}
android::Parcel* p = android::parcelForJavaObject(env, parcel);
const bool isMutable = p->readInt32() != 0 ;
const SkBitmap::Config config = (SkBitmap::Config)p->readInt32();
const int width = p->readInt32();
const int height = p->readInt32();
const int rowBytes = p->readInt32();
const int density = p->readInt32();
if (SkBitmap::kARGB_8888_Config != config &&
SkBitmap::kRGB_565_Config != config &&
SkBitmap::kARGB_4444_Config != config &&
SkBitmap::kIndex8_Config != config &&
SkBitmap::kA8_Config != config) {
SkDebugf("Bitmap_createFromParcel unknown config: %d\n" , config);
return NULL;
}
SkBitmap* bitmap = new SkBitmap;
bitmap->setConfig(config, width, height, rowBytes);
SkColorTable* ctable = NULL;
if (config == SkBitmap::kIndex8_Config) {
int count = p->readInt32();
if (count > 0 ) {
size_t size = count * sizeof (SkPMColor);
const SkPMColor* src = (const SkPMColor*)p->readInplace(size);
ctable = new SkColorTable(src, count);
}
}
jbyteArray buffer = GraphicsJNI::allocateJavaPixelRef(env, bitmap, ctable);
if (NULL == buffer) {
SkSafeUnref(ctable);
delete bitmap;
return NULL;
}
SkSafeUnref(ctable);
size_t size = bitmap->getSize();
android::Parcel::ReadableBlob blob;
android::status_t status = p->readBlob(size, &blob);
if (status) {
doThrowRE(env, "Could not read bitmap from parcel blob." );
delete bitmap;
return NULL;
}
bitmap->lockPixels();
memcpy (bitmap->getPixels(), blob.data(), size);
bitmap->unlockPixels();
blob.release();
return GraphicsJNI::createBitmap(env, bitmap, buffer, getPremulBitmapCreateFlags(isMutable),
NULL, NULL, density);
}
然后是 Parcel 的 readBlob:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
status_t Parcel::readBlob(size_t len, ReadableBlob* outBlob) const
{
int32_t useAshmem;
status_t status = readInt32(&useAshmem);
if (status) return status;
if (!useAshmem) {
ALOGV("readBlob: read in place" );
const void * ptr = readInplace(len);
if (!ptr) return BAD_VALUE;
outBlob->init(false , const_cast <void *>(ptr), len);
return NO_ERROR;
}
ALOGV("readBlob: read from ashmem" );
int fd = readFileDescriptor();
if (fd == int (BAD_TYPE)) return BAD_VALUE;
void * ptr = ::mmap(NULL, len, PROT_READ, MAP_SHARED, fd, 0 );
if (!ptr) return NO_MEMORY;
outBlob->init(true , ptr, len);
return NO_ERROR;
}
然后最后是释放共享内存。前面 Proc A 写完后,Blob 的 release 只是 munmap 了而已,Proc B 也是读完,重新创建完 Bitmap 后,也是 release 只是 munmap。我们来看看是在哪里关闭 fd 的。本着谁 open、谁 close 的原则,应该是 Proc A 这边关闭的。后面有篇内存管理篇的, Parcel 的析构函数会调用 freeDataNoInit:
1
2
3
4
5
6
7
8
9
10
11
12
void Parcel::freeDataNoInit()
{
if (mOwner) {
mOwner(this , mData, mDataSize, mObjects, mObjectsSize, mOwnerCookie);
} else {
releaseObjects();
if (mData) free (mData);
if (mObjects) free (mObjects);
}
}
内存管理那里是设置了 mOwner 了的,所以跑的是自己的 freeBuffer 回调,这里走的是下面,那主要是看 releaseObjects:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
void Parcel::releaseObjects()
{
const sp<ProcessState> proc(ProcessState::self());
size_t i = mObjectsSize;
uint8_t* const data = mData;
size_t* const objects = mObjects;
while (i > 0 ) {
i--;
const flat_binder_object* flat
= reinterpret_cast <flat_binder_object*>(data+objects[i]);
release_object(proc, *flat, this );
}
}
void release_object(const sp<ProcessState>& proc,
const flat_binder_object& obj, const void * who)
{
switch (obj.type) {
... ...
case BINDER_TYPE_FD: {
if (obj.cookie != (void *)0 ) close(obj.handle);
return ;
}
}
ALOGE("Invalid object type 0x%08lx" , obj.type);
}
果然是在 Proc A 关闭 fd 的咧,前面 writeFileDescriptor 那里设置的 takeOwnership 是 true,所以 flat_binder_object 的 cookie 是 1 。Parcel 析构的时候,正好可以 close 掉 fd。一般 IPC 通信,Proc A 传过去的 Parcel 都是局部变量,等 IPC 通信完成,就析构了(Proc B 那边也用完了,所以这个时候 close 是安全的)。
所以从上面来看,java 层的 MemroyFile 确实没啥用,不过感觉可以用 Parcel 来代替咧,Parcel 的 Blob 就是封装好的 ashmem,也有 read、write 接口。然后如果在 binder 中传递 Bitmap 的话,使用 ashmem 需要 copy 2次 bitmap 的 pixels 数据,这个 android 应该是出于安全性考虑,把原始的 bitmap copy 了一份出来,扔 ashmem 里面,然后对方再申请一片空间把 ashmem 里的内容 copy 过去。这样话,Proc A 后面怎么折腾原始的 bitmap 都不会对 Proc B 的 bitmap有影响(包括 recycle)。
当然这样在高性能的环境下是不行的,可以自己通过 Parcel 的接口改造一下: Proc A 创建 ashmem,拿 ashmem 的 buffer 解码 bitmap,然后传 ashmem 给 Proc B,Proc B 直接在 ashmem 的 buffer 上再创建出 Bitmap。不过这样带来的风险就是你自己要管理好 ashmem 的 buffer,确保 Proc B 不用了,才能 munmap、close 。好像 SurfacFlinger 用的就是类似这样的方案,这个后面有时间再慢慢说。所以说不要有事没事跨进程传图片,还是大图片。
最后来个对比,如果 bitmap 不用 ashmem 传递,把 binder mmap 的内存改大,那么使用普通内存传递,需要 3次 copy(Proc A、Proc B 各自一次,Proc A —> kernel 一次)。如果使用普通的 IPC 那么需要 4次 copy(Proc A、Proc B 各自一次,Proc A —> kernel, kernel —> Proc B)。