android 为了高效的 IPC 通信做了很多工作,内存管理就属于其中之一。传统的 IPC 传递数据,至少需要2次拷贝,一次为进程1到内核,一次为内核到进程2,但是得益 android binder 的内存管理,数据拷贝只有1次,就从这里速度比传统的要快1倍。这里慢慢分析。还是先说下相关代码的位置(其实还有很多 linux 编程的相关基础知识):
1 2 3 4 5 6 7 8 9
| frameworks/native/include/binder frameworks/native/libs/binder kernel/drivers/staging/android/binder.h kernel/drivers/staging/android/binder.c
|
基础知识
首先得说下一些相关的基础知识。这里很多我都是找网上现成的,因为这方面的基础知识我几乎为0 -_-||。先说下,为什么 linux 要使用虚拟地址映射物理地址,内存为什么要分页:
Linux中的内存管理
然后还有这篇有介绍 linux 用户空间和内核空间的:
Linux用户空间与内核空间
然后 linux 中的内存是分页的,也就是说要按照页大小对齐。这个在后面内存分配那里能够体现出来,这里先提前说一下。
原理
前面几篇也说过了,IPC 中最基本的问题在于进程间使用的虚拟地址空间是相互独立的,不能直接访问,所以要相互访问,就要借助 kernel ,就是要让数据用用户空间进入到内核空间,然后再去到另一个进程的用户空间。传统的 IPC 是这样的,其实 binder 也是这样的,不过它把内核空间的地址和用户空间的虚拟地址映射到了同一段物理地址上,所以就只需要把数据从原始用户空间复制到内核空间,把目标进程用户空间和内核空间映射到同一段物理地址,这样第一次复制到内核空间,其实目标的用户空间上也有这段数据了。这就是 binder 比传统 IPC 高效的一个原因。
这么抽象的文字,不太好理解吧,下面从代码慢慢看吧:
只复制一次的实现
首先 ProcessState 初始化的构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| ProcessState::ProcessState() : mDriverFD(open_driver()) , mVMStart(MAP_FAILED) , mManagesContexts(false) , mBinderContextCheckFunc(NULL) , mBinderContextUserData(NULL) , mThreadPoolStarted(false) , mThreadPoolSeq(1) { if (mDriverFD >= 0) { #if !defined(HAVE_WIN32_IPC) mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0); if (mVMStart == MAP_FAILED) { ALOGE("Using /dev/binder failed: unable to mmap transaction memory.\n"); close(mDriverFD); mDriverFD = -1; } #else mDriverFD = -1; #endif } }
|
那个 open_driver() 是打开 /dev/binder 这个设备节点。额,这里多扯下这个设备节点相关的知识。这个是 android 为 binder 驱动创建的虚拟设备节点。什么叫虚拟的咧,像触摸屏、传感器这些设备节点是有真实的物理设备的,但是 binder 确没有,只是为 IPC 创建的驱动而已,所以是虚拟的。android 上 linux 不支持动态创建设备节点,所有的设备节点都是通过 system/core/init 这个 init 程序创建的。这个东西有个配置文件,可以配置要创建哪里设备节点,默认的在 system/core/rootdir/ueventd.rc 这个文件中:
/dev/null 0666 root root
/dev/zero 0666 root root
/dev/full 0666 root root
/dev/ptmx 0666 root root
/dev/tty 0666 root root
/dev/random 0666 root root
/dev/urandom 0666 root root
/dev/ashmem 0666 root root
/dev/binder 0666 root root
可以在 devices 下面 ueventd.xx.rc 加上自己机器板子上相关的设备节点。
好,回到打开 /dev/binder 那,这里有个 mmap ,前面有一篇说到这里看注释这是映射给 binder 驱动接受数据用的 buffer,但是你搜索完整个 binder 模块(frameworks/native/lib/binder)发现没一个地方使用 mVMStart 这个返回的映射地址空间。注意一下 mmap 设置的标志: PROT_READ 。这个标志说明映射的这段内存是只读的,当然在这个模块没使用(其实读也没用到)。
其实映射的这段内存是内核的 binder 驱动在使用,同时也在管理,而且这里也是前面提到的 IPC 中只复制一次的实现的地方。
我们去 binder 驱动中看下, mmap 经过系统调用,最后会调用 binder 驱动的 binder_mmap:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
| static int binder_mmap(struct file *filp, struct vm_area_struct *vma) { int ret; struct vm_struct *area; struct binder_proc *proc = filp->private_data; const char *failure_string; struct binder_buffer *buffer; if ((vma->vm_end - vma->vm_start) > SZ_4M) vma->vm_end = vma->vm_start + SZ_4M; if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) { ret = -EPERM; failure_string = "bad vm_flags"; goto err_bad_arg; } vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE; if (proc->buffer) { ret = -EBUSY; failure_string = "already mapped"; goto err_already_mapped; } area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP); if (area == NULL) { ret = -ENOMEM; failure_string = "get_vm_area"; goto err_get_vm_area_failed; } proc->buffer = area->addr; proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer; #ifdef CONFIG_CPU_CACHE_VIPT if (cache_is_vipt_aliasing()) { while (CACHE_COLOUR((vma->vm_start ^ (uint32_t)proc->buffer))) { printk(KERN_INFO "binder_mmap: %d %lx-%lx maps %p bad alignment\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer); vma->vm_start += PAGE_SIZE; } } #endif proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL); if (proc->pages == NULL) { ret = -ENOMEM; failure_string = "alloc page array"; goto err_alloc_pages_failed; } proc->buffer_size = vma->vm_end - vma->vm_start; vma->vm_ops = &binder_vm_ops; vma->vm_private_data = proc; if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) { ret = -ENOMEM; failure_string = "alloc small buf"; goto err_alloc_small_buf_failed; } buffer = proc->buffer; INIT_LIST_HEAD(&proc->buffers); list_add(&buffer->entry, &proc->buffers); buffer->free = 1; binder_insert_free_buffer(proc, buffer); proc->free_async_space = proc->buffer_size / 2; barrier(); proc->files = get_files_struct(current); proc->vma = vma; printk(KERN_INFO "binder_mmap: %d %lx-%lx maps %p\n", proc->pid, vma->vm_start, vma->vm_end, proc->buffer); return 0; err_alloc_small_buf_failed: kfree(proc->pages); proc->pages = NULL; err_alloc_pages_failed: vfree(proc->buffer); proc->buffer = NULL; err_get_vm_area_failed: err_already_mapped: err_bad_arg: printk(KERN_ERR "binder_mmap: %d %lx-%lx %s failed %d\n", proc->pid, vma->vm_start, vma->vm_end, failure_string, ret); return ret; }
|
额,从这开始要涉及到内核的一些相关知识,我其实对这些一窍不通,这里推荐去看下这里:
binder驱动———-之内存映射篇
其实我能弄明白 binder 的内存管理,很大程序上得感觉这篇博文的博,他已经说得挺清楚了的,但是还是自己再整一次记得比较深。
对应程序 map 内存的情况,可以通过 cat /proc/pid/maps 查看,普通走 android binder 封装的程序(就是 ProcessState 那)映射的内存大小是 1M 左右:
#define BINDER_VM_SIZE ((1*1024*1024) - (4096 *2))
唯独特殊的 servicemanager (它是直接通过 ioctl 来使用 binder 的)映射的内存比较小(frameworks/base/cmds/servicemanager/service_manager.c):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| int main(int argc, char **argv) { struct binder_state *bs; void *svcmgr = BINDER_SERVICE_MANAGER; bs = binder_open(128*1024); if (binder_become_context_manager(bs)) { ALOGE("cannot become context manager (%s)\n", strerror(errno)); return -1; } svcmgr_handle = svcmgr; binder_loop(bs, svcmgr_handler); return 0; }
|
这片内存是接收 IPC 中客户发送过来的数据的,所以之前网上有人说使用 bundle 在 activity 之间传递数据不能太大,如果超过 1M 就会出现错误。现在明白了吧,bundle 最后是通过 binder 来传递数据的,底层接收数据的 buffer 一共才 1M(其实比1M小点,还减了8k去咧),超过 1M 肯定就失败啦。那 servicemanager 为什么才开 128k 的空间呢,去看看 servicemanager 的接口就知道了,它一共才3个接口:addService、getSerivce、checkSerivce,参数都没几个,所以 128k 肯定够了。上张图来看看吧:
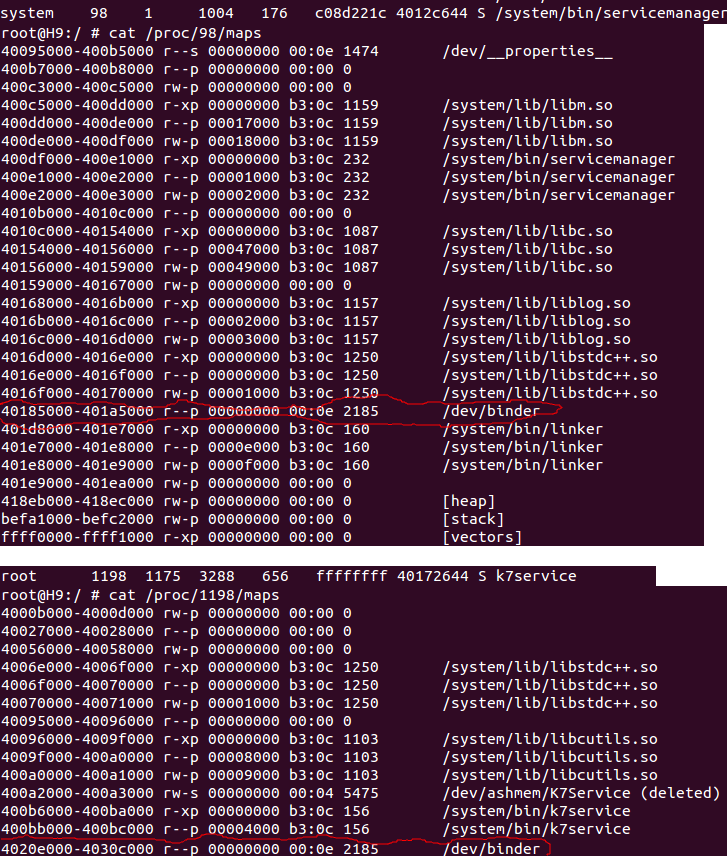
servermanager /dev/binder map 的内存区域是: 40185000 - 401a5000(16进制的) 正好是 128*1024。那个 k7service 是我写的一个测试的 native 小程序(Bn端的),它 /dev/binder map 的内存区域是: 4020e000 - 4030c000,也正好是 1M - 4k。
vma 这个变量是 mmap 调用后,系统传过来的,包含了内核分配给这次 mmap 映射的内存地址的一些信息,其中就有比较重要的起始和结束地址: vma->vm_start 和 vma->vm_end。然后我们慢慢往下看,后面通过传递过来的地址计算出要映射的内存大小(这里注意下,vma 里面地址是用户空间的地址),然后使用 get_vm_area 这个调用向内核申请一片内存空间。这个申请的是内核空间的内存,感觉有点像上层的 malloc,我对这个也不是很了解,只能先这么认为了。再注意一点这里只是向内核申请了一片内存空间而已,还是真正的分配物理地址(建立虚拟地址到物理地址的映射关系)。
申请成功后,会返回一个 vm_struct 的结构,里面有描述这片内存区域的信息,这里把内核这片区域的起始地址 addr 保存在了 proc->buffer 这个变量里面。然后后面那个 proc->user_buffer_offset 这个变量的计算很关键:
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
拿用户空间的地址去减内核空间的地址,得到这2个地址的偏移量(这个名字取得也很直接: user_buffer_offset)。前面给的一篇参考文章里说到,32位的 linux(目前的 android 还都是32位的)总共可用内存空间 4G,0G~3G 为用户空间(也就是应用程序使用的空间),3G~4G 为内核空间,用户空间无法访问内核空间,但是内核空间可以访问用户空间。所以这里申请到内核空间的地址,然后拿 mmap 传递过来的用户空间的地址去减得到偏移。但是这里有个奇怪的地方我不太理解的,这里是拿低地址 - 高地址,得到的应该是负数,但是地址是无符号的,所以得到的是 0xffffffff 减去的数值,然后后面拿这个值加上用户空间地址还能正确的得到内核空间地址,反正我是醉了。在 binder 里加了点打印,上个图来点真相(是我写的那个 k7service 的小程序):

1198 是 k7service 的 pid,然后分配的用户空间范围是: 4020e000 - 4030c000(和前面 cat 看到的一样),然后分配的内核空间起始地址是: e2f00000,确实是从 3G(0xc0000000)开始的。
后面 proc->buffer_size 就是用 mmap 传过来的地址一减就能得到映射内存的大小。后面 binder_update_page_range 这个函数是同时映射用户空间和内核空间,调用这个才是真正的分配物理地址,这个后面再说。
proc->pages 是一个指向指针的指针,struct page 是内核的代表内存页的数据结构。前面也说了 linux 带 MMU 的内存管理都是分页的(现在跑 android 的芯片基本都带 MMU)。这里是拿内核一页的大小(经过打印我手上的板子上 PAGE_SIZE 是 4096,也就是 4k,一般都是这大小吧),算出 mmap 映射的内存一共可以分为几页,然后事先先把保存内核页的数据结构的数组分配好。
然后后面那句: buffer = proc->buffer;。proc->buffer 是这片内存内核空间的首地址,这个 buffer 是一个叫 binder_buffer 的结构体,用来表示 binder 分配内存的块的一个块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| struct binder_buffer { struct list_head entry; struct rb_node rb_node; unsigned free:1; unsigned allow_user_free:1; unsigned async_transaction:1; unsigned debug_id:29; struct binder_transaction *transaction; struct binder_node *target_node; size_t data_size; size_t offsets_size; uint8_t data[0]; };
|
前面的变量都先不说,注意看最后那个叫 data[0] 的变量。这个 data 其实表示的是地址来的。这个是怎么回事咧,其实 binder mmap 这一片内存中,是分成一块块的(binder_buffer),内存中的排列是这样的:

每一块数据前面跟着一个 binder_buffer,然后紧着下一个,一个跟一个保存在 proc->buffers 这个链表里。然后再看看刚刚说的那句:buffer = proc->buffer; 。这句话相当于是说:
- 分配内核第一块
binder_buffer。
- 同时,
proc->buffer 这个首地址就是第一个块 binder_buffer,并且 binder_buffer 的 data 就是这块 binder_buffer 指向的数据地址。所以这个 data 必须要放在这个结构体的最后(kernel 的链表实现则是利用结构体的首变量(地址),在这种淫荡的技能上,c 秒杀 java)。
这种简洁、高效的办法,kernel 的代码中有不少,可以好好运用一下。
然后后面是把刚刚分配好的这块 binder_buffer 分别插入到 proc 的 buffers 链表和 free_buffers 红黑树中。这里稍微看下 binder_proc 中几个相关的成员变量:
1 2 3 4 5 6 7 8 9 10 11
| struct binder_proc { ... ... struct list_head buffers; struct rb_root free_buffers; struct rb_root allocated_buffers; size_t free_async_space; ... ... };
|
这几个变量分别代表:
- buffers: 这个链表保存了所有已经分配的
binder_buffer 内存块。
free_buffers: 这个红黑树保持了还未使用的 binder_buffer 内存块,就是已经分配了,但是没还创建物理内存映射的,说是分配倒不如说创建的好理解点,就是说 binder_buffer 这个结构体已经创建,然后在那片内存中占了个空位,要申请内存,可以不用重新创建对象,不用重新再那片内存重新分配。使用红黑树提高查找速度,按 binder_buffer 的 size 排列(后面的查找算法,会发现使用红黑树的好处)。allocated_buffers:这里保存的是已经建立好物理内存映射的 binder_buffer 内存块,也是说正在使用中的 binder_buffer。也是一颗红黑树。
所以理论上,proc->buffers 里有所有的 binder_buffer,然后 proc->buffers 的里的是 proc->free_buffers 和 allocated_buffers 之和。
一般用法是刚开始新分配一个 binder_buffer 插入到 proc->buffers 里,同时也插入 proc->free_buffers 里。binder_mmap 就是一开是分配了一个 binder_buffer。然后后面数据来了,要申请使用 binder_buffer 会先在 proc->free_buffers 里查找大小最接近要求的 binder_buffer 块,然后调用 binder_update_page_range 将这块 binder_buffer 的用户空间地址和内核地址映射到物理地址(真正的分配内存),然后把这块 binder_buffer 从 proc->free_buffers 中删掉,再插入到 allocated_buffers 中。然后重复。当然里面还有不少细节,还有内存管理相关的,这些后面再说。
这里 binder_mmap 差不多看完了,那回去看看那个 binder_update_page_range,这个是将用户地址和内核地址映射到同一物理地址上,来看看是怎么做到的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103
| static int binder_update_page_range(struct binder_proc *proc, int allocate, void *start, void *end, struct vm_area_struct *vma) { void *page_addr; unsigned long user_page_addr; struct vm_struct tmp_area; struct page **page; struct mm_struct *mm; if (end <= start) return 0; if (vma) mm = NULL; else mm = get_task_mm(proc->tsk); if (mm) { down_write(&mm->mmap_sem); vma = proc->vma; } if (allocate == 0) goto free_range; if (vma == NULL) { printk(KERN_ERR "binder: %d: binder_alloc_buf failed to " "map pages in userspace, no vma\n", proc->pid); goto err_no_vma; } for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) { int ret; struct page **page_array_ptr; page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE]; BUG_ON(*page); *page = alloc_page(GFP_KERNEL | __GFP_ZERO); if (*page == NULL) { printk(KERN_ERR "binder: %d: binder_alloc_buf failed " "for page at %p\n", proc->pid, page_addr); goto err_alloc_page_failed; } tmp_area.addr = page_addr; tmp_area.size = PAGE_SIZE + PAGE_SIZE ; page_array_ptr = page; ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr); if (ret) { printk(KERN_ERR "binder: %d: binder_alloc_buf failed " "to map page at %p in kernel\n", proc->pid, page_addr); goto err_map_kernel_failed; } user_page_addr = (uintptr_t)page_addr + proc->user_buffer_offset; ret = vm_insert_page(vma, user_page_addr, page[0]); if (ret) { printk(KERN_ERR "binder: %d: binder_alloc_buf failed " "to map page at %lx in userspace\n", proc->pid, user_page_addr); goto err_vm_insert_page_failed; } } if (mm) { up_write(&mm->mmap_sem); mmput(mm); } return 0; free_range: for (page_addr = end - PAGE_SIZE; page_addr >= start; page_addr -= PAGE_SIZE) { page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE]; if (vma) zap_page_range(vma, (uintptr_t)page_addr + proc->user_buffer_offset, PAGE_SIZE, NULL); err_vm_insert_page_failed: unmap_kernel_range((unsigned long)page_addr, PAGE_SIZE); err_map_kernel_failed: __free_page(*page); *page = NULL; err_alloc_page_failed: ; } err_no_vma: if (mm) { up_write(&mm->mmap_sem); mmput(mm); } return -ENOMEM; }
|
一开始有个 end <= start 的判断,后面会发现,当 end == start 的时候是表示这段内存已经映射过了。然后是那第二参数,为 0 的时候表示释放映射,我们先看映射的情况。下面是一个循环,前面说了 linux 内存是分页的,所以就要一页一页的映射,这里就是从映射起始地址到结束看需要映射几页。然后循环开始通过地址算出当前地址所在的页在之前创建的页数组中的位置,proc->pages 前面 mmap 那里提前创建好了。然后是 alloc_page 申请内核页面,以后有时间补补相关知识,现在暂时理解为 malloc 差不多就行了。后面设置这个页面的地址,然后大小的时候不知道为什么多加了 PAGE_SIZE 大小,看注释是说防止页面越界?? map_vm_area 把刚刚设置的内核页面做物理内存映射,到这里才算真正分配内存。
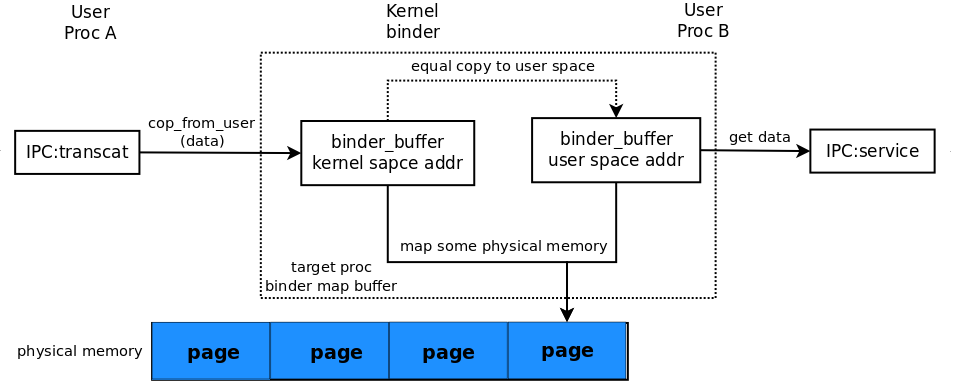
这里 proc->user_buffer_offset 这个前面保存的内核到用户地址的偏移终于派上用场了。通过这个偏移可以算得出内核空间地址对应的用户空间地址。然后 vm_insert_page 把这段用户空间地址也做一次物理内存映射。这样内核空间地址和用户空间的地址就映射到同一块物理内存上了。这里由于缺少相关的知识我还是不怎么理解,这几个内核的 api 调用是咋回事,但是简单来说:如果你在 binder 驱动对内核这段地址的内存写入数据,对应用户空间的那段内存也会有同样的数据。这样就省去了一次 copy_to_user 的从内核空间到用户空间的数据 copy。
最后来张图吧,这样比较简单明了:
实际运用
前面说了那么多,来点例子看看是怎么运用只 copy 一次的。假设有个 proc A 发起了一次 IPC 调用,那么根据前面的讲解会通过 IPCThreadState.transact 发送到 binder 的 binder_thread_write 写请求,然后是跑到了 binder_thread_transaction 中。我们这里来看看前面 binder_transaction 中忽略的一些细节。在 binder_transaction 有这么一句:
t->buffer = binder_alloc_buf(target_proc, tr->data_size,
tr->offsets_size, !reply && (t->flags & TF_ONE_WAY));
这里跑到了 binder_alloc_buf 里面,这个函数后面在内存管理那里再分析,这里向跳过,反正记住调用这个会给你返回一块符合你指定大小的 buffer_size(当然得有足够的内存空间)。然后这里注意一点,传递的一个参数是 target_proc,这个是从目标进程分配的 buffer,也就是 proc B。这个很关键,后面就能知道数据是怎么传递的了。然后接着看后面的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| offp = (size_t *)(t->buffer->data + ALIGN(tr->data_size, sizeof(void *))); if (copy_from_user(t->buffer->data, tr->data.ptr.buffer, tr->data_size)) { binder_user_error("binder: %d:%d got transaction with invalid " "data ptr\n", proc->pid, thread->pid); return_error = BR_FAILED_REPLY; goto err_copy_data_failed; } if (copy_from_user(offp, tr->data.ptr.offsets, tr->offsets_size)) { binder_user_error("binder: %d:%d got transaction with invalid " "offsets ptr\n", proc->pid, thread->pid); return_error = BR_FAILED_REPLY; goto err_copy_data_failed; }
|
这个 buffer->data 的淫荡前面分析过了,这个就是这块 buffer 的存放数据的首地址。唉,这里其实调用了2次 copy_from_user 一次 copy parcel 的 data 数据,一次 copy parcel 里 flat_binder_object 的偏移地址的数据(-_-||)。其实我们就将就认为只有一次 copy 吧。这里就把 proc A 从用户空间传递过来的数据(parcel 打包)copy 到内核空间了。而且这个内核空间的内存是 proc B 提供的,而且这个块内核空间还和 proc B 的用户空间共同映射到了同一块物理内存上。
但是别激动先,我们把整个流程看完。根据前面的分析 binder_transaction 后面把从 proc B 获取了 binder_buffer 的 binder_transaction 这个数据结构插入到 proc B 的 work 队列中并且唤醒阻塞等待数据的 proc B 的 binder_thread_read。我们来看看 binder_thread_read 中前面忽略的一些比较重要的地方:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| tr.data_size = t->buffer->data_size; tr.offsets_size = t->buffer->offsets_size; tr.data.ptr.buffer = (void *)t->buffer->data + proc->user_buffer_offset; tr.data.ptr.offsets = tr.data.ptr.buffer + ALIGN(t->buffer->data_size, sizeof(void *)); if (put_user(cmd, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (copy_to_user(ptr, &tr, sizeof(tr))) return -EFAULT; ptr += sizeof(tr);
|
t 就是从前面 proc A binder_transaction 插到 proc B 的 work 队列里的,然后从它这里获取 data_size, offsets_size 之类,这些都是前面设置好的。然后观点的地方来了:
tr.data.ptr.buffer = (void *)t->buffer->data +
proc->user_buffer_offset;
tr 是 binder_transaction_data 这个数据结构,是在用户层和 binder 驱动传递数据的数据结构。直接取 buffer->data + user_buffer_offset 这个地址。根据前面的分析 buffer->data 是前面 proc A 塞数据的内核地址,user_buffer_offset 是用内核地址到用户空间地址的偏移,一加就得到了同一物理地址的用户空间地址。这里其实就差不多相当于数据从 proc A 传递到 proc B 了。这里就相当于传递 IPC 内核到用户空间的那一次 copy,但是这里只是计算了一个地址偏移而已。
然后看看后面, put_user 是把 binder 命令(cmd)返回给用户空间。还有后面有一个 copy_to_user 但是这个不是 copy 数据的,而是 copy binder_transaction_data 这个数据结构,只不过这个数据结构里有传递数据的地址,所以这个不算在 binder 数据传递的复制次数中。也就是说就算传递比较大的数据,这次复制只是复制一个数据结构的大小。根据前面的分析,binder_thread_read 返回,binder_ioctl 就返回了,然后就到用户空间的 IPCThreadState 的 talkWithDriver,然后 proc B(从假设的例子看是 Bn 端)就该执行 executeCommand 的 BR_TRANSACTION 命令:
1 2 3 4 5 6 7 8 9 10 11 12 13
| binder_transaction_data tr; result = mIn.read(&tr, sizeof(tr)); ALOG_ASSERT(result == NO_ERROR, "Not enough command data for brTRANSACTION"); if (result != NO_ERROR) break; Parcel buffer; buffer.ipcSetDataReference( reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast<const size_t*>(tr.data.ptr.offsets), tr.offsets_size/sizeof(size_t), freeBuffer, this);
|
看 binder_transaction_data 从 mIn 中读出来了吧,这个是前面 binder_thread_read copy_to_user 传递到用户空间的。然后这个里面的 tr.data.ptr.buffer 就是 proc A 传递的 IPC 函数调用参数数据啦。
内存管理
前面把数据传递的基本流程走完了,最后看看内存管理。每一个 binder 通信的进程都 mmap 了一片内存(目前来看是 1M),然后在这片内存上按照请求分块(binder_buffer)。那一般就涉及到,如何分块,如果查找合适大小的 binder_buffer 块,以及使用完成后,碎片合并的问题。现在就来看看。
前面说了,一开始 binder 会映射一页的内存(一般是 4k),然后插入到 proc->free_buffers 中去。然后要需要使用的时候先从 free_buffers 里找大小最接近的,我们看看是怎么查找的,就是前面说的那个 binder_alloc_buf 函数啦:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118
| static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc, size_t data_size, size_t offsets_size, int is_async) { struct rb_node *n = proc->free_buffers.rb_node; struct binder_buffer *buffer; size_t buffer_size; struct rb_node *best_fit = NULL; void *has_page_addr; void *end_page_addr; size_t size; if (proc->vma == NULL) { printk(KERN_ERR "binder: %d: binder_alloc_buf, no vma\n", proc->pid); return NULL; } size = ALIGN(data_size, sizeof(void *)) + ALIGN(offsets_size, sizeof(void *)); if (size < data_size || size < offsets_size) { binder_user_error("binder: %d: got transaction with invalid " "size %zd-%zd\n", proc->pid, data_size, offsets_size); return NULL; } if (is_async && proc->free_async_space < size + sizeof(struct binder_buffer)) { binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: binder_alloc_buf size %zd" "failed, no async space left\n", proc->pid, size); return NULL; } while (n) { buffer = rb_entry(n, struct binder_buffer, rb_node); BUG_ON(!buffer->free); buffer_size = binder_buffer_size(proc, buffer); if (size < buffer_size) { best_fit = n; n = n->rb_left; } else if (size > buffer_size) n = n->rb_right; else { best_fit = n; break; } } if (best_fit == NULL) { printk(KERN_ERR "binder: %d: binder_alloc_buf size %zd failed, " "no address space\n", proc->pid, size); return NULL; } if (n == NULL) { buffer = rb_entry(best_fit, struct binder_buffer, rb_node); buffer_size = binder_buffer_size(proc, buffer); } binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: binder_alloc_buf size %zd got buff" "er %p size %zd\n", proc->pid, size, buffer, buffer_size); has_page_addr = (void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK); if (n == NULL) { if (size + sizeof(struct binder_buffer) + 4 >= buffer_size) buffer_size = size; else buffer_size = size + sizeof(struct binder_buffer); } end_page_addr = (void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size); if (end_page_addr > has_page_addr) end_page_addr = has_page_addr; if (binder_update_page_range(proc, 1, (void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL)) return NULL; rb_erase(best_fit, &proc->free_buffers); buffer->free = 0; binder_insert_allocated_buffer(proc, buffer); if (buffer_size != size) { struct binder_buffer *new_buffer = (void *)buffer->data + size; list_add(&new_buffer->entry, &buffer->entry); new_buffer->free = 1; binder_insert_free_buffer(proc, new_buffer); } binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: binder_alloc_buf size %zd got " "%p\n", proc->pid, size, buffer); buffer->data_size = data_size; buffer->offsets_size = offsets_size; buffer->async_transaction = is_async; if (is_async) { proc->free_async_space -= size + sizeof(struct binder_buffer); binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC, "binder: %d: binder_alloc_buf size %zd " "async free %zd\n", proc->pid, size, proc->free_async_space); } return buffer; }
|
先说说这个函数的参数,第一个前面说了是目标进程的。后面2个 size 分别是 proc A 使用 parcel 打包的 data size 和 flat_binder_object 偏移数据的 size(见前一篇分析)(最后那个异步释放先不管)。这2个 size 加起来就是总共需要空间。然后后面那个 while 循环,是在从 free_buffers 的根开始查找大小合适的 buffer。free_buffers 红黑树按照大小排列,左子树一定比当前节点小,右子树一定比当前节点大。然后我们看下 binder_buffer_size 这个函数:
1 2 3 4 5 6 7 8 9 10
| static size_t binder_buffer_size(struct binder_proc *proc, struct binder_buffer *buffer) { if (list_is_last(&buffer->entry, &proc->buffers)) return proc->buffer + proc->buffer_size - (void *)buffer->data; else return (size_t)list_entry(buffer->entry.next, struct binder_buffer, entry) - (size_t)buffer->data; }
|
这个函数是获取指定 binder_buffer 的大小,从实现可以看得出:
- 如果这块 buffer 是最后那块,那么返回的后面剩下整块内存空间的大小。
- 如果这块 buffer 在中间,那么大小就是后面那块地址 - 当前这块地址。
结合这2点可以看出这些 binder_buffer 在那 1M 的内存块中是连续排列的(这也为后面合并碎片块提供了便利性)。
从上面就能知道,如果这 1M 当中还有大于要求 size 的大小,就一定能找得到,就算分配的 buffer 没有这么大,如果找到最后那块,就是整个剩余空间的大小了。当然如果整个剩余空间都不够那就没办法了。所以上层应用写一些跨进程的功能的时候不要直接使用 binder 传递大于 1M 的数据(上面是 Bundle、Parcel 之类的),应该使用共享内存来传递(见前面一篇的分析)。
继续往下走,best_fit == NULL 表示没有足够的空间了(找不到比要求 size 大或者等于的 buffer 块)。然后能往后走说明 best_fit 这块至少是不小于要求 size 大小的。 n == NULL 这个判断就是说没找一块 buffer 大小正好是要求的 size 大小(实际上大小正好相等的情况是很少的),那么就意味要从这一块中分出 size 大小的出去另外做一块 buffer。所以后面重新计算了下 buffer_size 的大小,要加上 binder_buffer 结构体的大小,前面分析了,一块 buffer 前面是 binder_buffer 信息。
然后后面调用 binder_update_page_range 去映射物理内存。注意下,前面分析的,因为 linux 的内存是按页分的,所以映射的时候也要按页去映射,那就要按页对齐,一般一页是 4k,但是很多参数其实就几个、十几个字节。所以这里起始地址和结束地址一对齐很多情况都是相等的。所以前面那个 binder_update_page_range 有个判断是 end >= start 就返回,这里如果 end == start 就表示这段内存已经映射过了(在同一页中)。
再后面就是把要用的那快 buffer 从 free_buffers 中删掉,然后把 free 标志改成正在使用的,插入到 allocated_buffers 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
| static void binder_insert_allocated_buffer(struct binder_proc *proc, struct binder_buffer *new_buffer) { struct rb_node **p = &proc->allocated_buffers.rb_node; struct rb_node *parent = NULL; struct binder_buffer *buffer; BUG_ON(new_buffer->free); while (*p) { parent = *p; buffer = rb_entry(parent, struct binder_buffer, rb_node); BUG_ON(buffer->free); if (new_buffer < buffer) p = &parent->rb_left; else if (new_buffer > buffer) p = &parent->rb_right; else BUG(); } rb_link_node(&new_buffer->rb_node, parent, p); rb_insert_color(&new_buffer->rb_node, &proc->allocated_buffers); }
|
可以看到 allocated_buffers 是按地址排列的。然后后面那个判断 buffer_size != size,如果前面找不到大小一样的 buffer 块,然后重新计算了 buffer_size, 那么如果这块 buffer 的大小比原来 size 大(这里肯定是大的,如果小的话就表示内存不够了)就要原来那块一分为二,前面拿 size 大小去用,后面剩下的作为空闲块。所以新弄了一个 binder_buffer 出来,然后把插入到 free_buffers 和 proc->buffers 里去了。那个 proc->buffers 是个链表,这里 list_add(&new_buffer->entry, &buffer->entry); 这种写法就是插入到这个链表的最后。然后来看插入到 free_buffers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| static void binder_insert_free_buffer(struct binder_proc *proc, struct binder_buffer *new_buffer) { struct rb_node **p = &proc->free_buffers.rb_node; struct rb_node *parent = NULL; struct binder_buffer *buffer; size_t buffer_size; size_t new_buffer_size; BUG_ON(!new_buffer->free); new_buffer_size = binder_buffer_size(proc, new_buffer); binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: add free buffer, size %zd, " "at %p\n", proc->pid, new_buffer_size, new_buffer); while (*p) { parent = *p; buffer = rb_entry(parent, struct binder_buffer, rb_node); BUG_ON(!buffer->free); buffer_size = binder_buffer_size(proc, buffer); if (new_buffer_size < buffer_size) p = &parent->rb_left; else p = &parent->rb_right; } rb_link_node(&new_buffer->rb_node, parent, p); rb_insert_color(&new_buffer->rb_node, &proc->free_buffers); }
|
这个函数主要注意 new_buffer_size = binder_buffer_size(proc, new_buffer); 。从这里可以看得出,这些空闲的 buffer 是不保存本块的大小的,都是要用的时候现场计算的。然后这里证实了 free_buffers 是按大小排列的了。
然后我们来看看使用完之后释放这些 buffer 块的情况。前一篇 parcel 那里说到 Parcel 里有一个叫 mOwner 的函数指针,如果设置了的话,会在 parcel 的析够函数里调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| Parcel::~Parcel() { freeDataNoInit(); } void Parcel::freeDataNoInit() { if (mOwner) { mOwner(this, mData, mDataSize, mObjects, mObjectsSize, mOwnerCookie); } else { releaseObjects(); if (mData) free(mData); if (mObjects) free(mObjects); } }
|
在 parcel 中设置 mOwner 的地方是 ipcSetDataReference 这个方法。然后在 IPCThreadState 有2个地方会调用 ipcSetDataReference 设置一个叫 freeBuffer 的函数:
一个是在 waitForResponse 中的 BR_REPLY 的命令那里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| case BR_REPLY: { binder_transaction_data tr; err = mIn.read(&tr, sizeof(tr)); ALOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY"); if (err != NO_ERROR) goto finish; if (reply) { if ((tr.flags & TF_STATUS_CODE) == 0) { reply->ipcSetDataReference( reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast<const size_t*>(tr.data.ptr.offsets), tr.offsets_size/sizeof(size_t), freeBuffer, this); } else { err = *static_cast<const status_t*>(tr.data.ptr.buffer); freeBuffer(NULL, reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast<const size_t*>(tr.data.ptr.offsets), tr.offsets_size/sizeof(size_t), this); } } else { freeBuffer(NULL, reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast<const size_t*>(tr.data.ptr.offsets), tr.offsets_size/sizeof(size_t), this); continue; } } goto finish;
|
一个是在 executeCommand 的 BR_TRANSACTION 的命令那:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
| case BR_TRANSACTION: { binder_transaction_data tr; result = mIn.read(&tr, sizeof(tr)); ALOG_ASSERT(result == NO_ERROR, "Not enough command data for brTRANSACTION"); if (result != NO_ERROR) break; Parcel buffer; buffer.ipcSetDataReference( reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer), tr.data_size, reinterpret_cast<const size_t*>(tr.data.ptr.offsets), tr.offsets_size/sizeof(size_t), freeBuffer, this); ... ... if (tr.target.ptr) { sp<BBinder> b((BBinder*)tr.cookie); const status_t error = b->transact(tr.code, buffer, &reply, tr.flags); if (error < NO_ERROR) reply.setError(error); } else { const status_t error = the_context_object->transact(tr.code, buffer, &reply, tr.flags); if (error < NO_ERROR) reply.setError(error); } ... ... } break;
|
然后回到通信篇那里去看看我之前画的那张图,注意设置 freeBuffer 全都是 BR 命令,一个是 executeCommand, 这个是 Bn 端那里。在 BR_TRANSACTION 命令里定义了一个本地变量 Parcel buffer,并且给这个 parcel 设置了 feeBuffer。然后作为参数传递给后面执行 Bn 端的 transaction 实现远程调用。然后这个 executeCommand 执行完后,就会执行 Parcel 的析够函数从而触发 freeBuffer 的调用。freeBuffer 的实现我们后面再说,里面是让 binder 去释放之前申请的 buffer 块。然后前面说了 proc A 发起 IPC,binder 里面是用 proc B(也就是 Bn 端)来的内存来申请 buffer 的。所以这里在 proc B 设置释放 buffer 的函数是合理的。
然后第二个 waitForResponse 也是差不多的。前面那个是在 Bn 端释放,是 Bp —> Bn 发送请求,target 是 Bn,这里呢是从 Bn 返回结果到 Bp,就是 Bn —> Bp, target 就是 Bp 了(proc A)。waitForResponse 的参数 Parcel reply 是从 Bp 的 IPCThreadState 的 transact 传递过来的,这个就是上层发起 IPC 那个接口函数传递过来的,也是一个本地变量,transact 调用完成后就会调用 Parcel 的析够函数触发释放函数。这里是从 Bn 返回到 Bp,申请的内存就是 Bp 端的,所以在 Bp 释放也是对的。
通过上面先得搞清楚,内存从哪个进程来的,在哪个进程释放。基本上在谁那拿的,就由谁来释放。搞清楚后,现在可以看看 freeBuffer 的实现了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| void IPCThreadState::freeBuffer(Parcel* parcel, const uint8_t* data, size_t dataSize, const size_t* objects, size_t objectsSize, void* cookie) { IF_LOG_COMMANDS() { alog << "Writing BC_FREE_BUFFER for " << data << endl; } ALOG_ASSERT(data != NULL, "Called with NULL data"); if (parcel != NULL) parcel->closeFileDescriptors(); IPCThreadState* state = self(); state->mOut.writeInt32(BC_FREE_BUFFER); state->mOut.writeInt32((int32_t)data); }
|
这个通过 mOut 对 binder 写了一个 BC_FREE_BUFFER 的命令,然后把保存的 buffer 块的用户空间的地址也写了进去。这些内存都是由 kernel 的 binder 驱动管理的,所以只能由 binder 驱动来释放,用户空间无法释放的。这样的话这个进程下次和 binder 进行通信的时候,就会由 BINDER_WRITE_READ ioctl 把这条命令写到 binder 驱动中去。binder 驱动就会执行 BC_FREE_BUFFER 释放使用完的 binder_buffer 内存块。还记得前面说 parcel 打包 binder 命令(或是解析)可以打包多条命令的么,这里就体现出来了。释放命令是随真正的业务命令一起打包发送过去的。
然后我们可以回到 binder 驱动里,看看 BC_FREE_BUFFER 的处理,这个在 binder_thread_write 里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
| case BC_FREE_BUFFER: { void __user *data_ptr; struct binder_buffer *buffer; if (get_user(data_ptr, (void * __user *)ptr)) return -EFAULT; ptr += sizeof(void *); buffer = binder_buffer_lookup(proc, data_ptr); if (buffer == NULL) { binder_user_error("binder: %d:%d " "BC_FREE_BUFFER u%p no match\n", proc->pid, thread->pid, data_ptr); break; } if (!buffer->allow_user_free) { binder_user_error("binder: %d:%d " "BC_FREE_BUFFER u%p matched " "unreturned buffer\n", proc->pid, thread->pid, data_ptr); break; } binder_debug(BINDER_DEBUG_FREE_BUFFER, "binder: %d:%d BC_FREE_BUFFER u%p found buffer %d for %s transaction\n", proc->pid, thread->pid, data_ptr, buffer->debug_id, buffer->transaction ? "active" : "finished"); if (buffer->transaction) { buffer->transaction->buffer = NULL; buffer->transaction = NULL; } if (buffer->async_transaction && buffer->target_node) { BUG_ON(!buffer->target_node->has_async_transaction); if (list_empty(&buffer->target_node->async_todo)) buffer->target_node->has_async_transaction = 0; else list_move_tail(buffer->target_node->async_todo.next, &thread->todo); } binder_transaction_buffer_release(proc, buffer, NULL); binder_free_buf(proc, buffer); break; }
|
通过 get_user 得到从用户空间传递过来要释放的 buffer 的地址。然后调用 binder_buffer_lookup 查找 buffer 块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
| static struct binder_buffer *binder_buffer_lookup(struct binder_proc *proc, void __user *user_ptr) { struct rb_node *n = proc->allocated_buffers.rb_node; struct binder_buffer *buffer; struct binder_buffer *kern_ptr; kern_ptr = user_ptr - proc->user_buffer_offset - offsetof(struct binder_buffer, data); while (n) { buffer = rb_entry(n, struct binder_buffer, rb_node); BUG_ON(buffer->free); if (kern_ptr < buffer) n = n->rb_left; else if (kern_ptr > buffer) n = n->rb_right; else return buffer; } return NULL; }
|
user_buffer_offset 的作用又来了,这里是通过用户空间地址计算出对应的内核空间地址。前面说了 allocated_buffers 是按地址排列的,所以通过地址查找。
然后后面先看看 binder_transaction_buffer_release 的释放:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75
| static void binder_transaction_buffer_release(struct binder_proc *proc, struct binder_buffer *buffer, size_t *failed_at) { size_t *offp, *off_end; int debug_id = buffer->debug_id; binder_debug(BINDER_DEBUG_TRANSACTION, "binder: %d buffer release %d, size %zd-%zd, failed at %p\n", proc->pid, buffer->debug_id, buffer->data_size, buffer->offsets_size, failed_at); if (buffer->target_node) binder_dec_node(buffer->target_node, 1, 0); offp = (size_t *)(buffer->data + ALIGN(buffer->data_size, sizeof(void *))); if (failed_at) off_end = failed_at; else off_end = (void *)offp + buffer->offsets_size; for (; offp < off_end; offp++) { struct flat_binder_object *fp; if (*offp > buffer->data_size - sizeof(*fp) || buffer->data_size < sizeof(*fp) || !IS_ALIGNED(*offp, sizeof(void *))) { printk(KERN_ERR "binder: transaction release %d bad" "offset %zd, size %zd\n", debug_id, *offp, buffer->data_size); continue; } fp = (struct flat_binder_object *)(buffer->data + *offp); switch (fp->type) { case BINDER_TYPE_BINDER: case BINDER_TYPE_WEAK_BINDER: { struct binder_node *node = binder_get_node(proc, fp->binder); if (node == NULL) { printk(KERN_ERR "binder: transaction release %d" " bad node %p\n", debug_id, fp->binder); break; } binder_debug(BINDER_DEBUG_TRANSACTION, " node %d u%p\n", node->debug_id, node->ptr); binder_dec_node(node, fp->type == BINDER_TYPE_BINDER, 0); } break; case BINDER_TYPE_HANDLE: case BINDER_TYPE_WEAK_HANDLE: { struct binder_ref *ref = binder_get_ref(proc, fp->handle); if (ref == NULL) { printk(KERN_ERR "binder: transaction release %d" " bad handle %ld\n", debug_id, fp->handle); break; } binder_debug(BINDER_DEBUG_TRANSACTION, " ref %d desc %d (node %d)\n", ref->debug_id, ref->desc, ref->node->debug_id); binder_dec_ref(ref, fp->type == BINDER_TYPE_HANDLE); } break; case BINDER_TYPE_FD: binder_debug(BINDER_DEBUG_TRANSACTION, " fd %ld\n", fp->handle); if (failed_at) task_close_fd(proc, fp->handle); break; default: printk(KERN_ERR "binder: transaction release %d bad " "object type %lx\n", debug_id, fp->type); break; } } }
|
前面 buffer 后面保存了 parcel flat_binder_object 的偏移数据,这里是去取这个偏移,然后通过这些偏移取到打包在 parcel 里面的 flat_binder_object 数据,然后去根据不同的类型去减少引用之类的(前面使用的时候会增加相应的引用)。我是比较讨厌这些啥引用计算的,这里就随便过过就行了。
然后看后面的 binder_free_buf, 这个和 binder_alloc_buf 真对应啊:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
| static void binder_free_buf(struct binder_proc *proc, struct binder_buffer *buffer) { size_t size, buffer_size; buffer_size = binder_buffer_size(proc, buffer); size = ALIGN(buffer->data_size, sizeof(void *)) + ALIGN(buffer->offsets_size, sizeof(void *)); binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: binder_free_buf %p size %zd buffer" "_size %zd\n", proc->pid, buffer, size, buffer_size); BUG_ON(buffer->free); BUG_ON(size > buffer_size); BUG_ON(buffer->transaction != NULL); BUG_ON((void *)buffer < proc->buffer); BUG_ON((void *)buffer > proc->buffer + proc->buffer_size); if (buffer->async_transaction) { proc->free_async_space += size + sizeof(struct binder_buffer); binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC, "binder: %d: binder_free_buf size %zd " "async free %zd\n", proc->pid, size, proc->free_async_space); } binder_update_page_range(proc, 0, (void *)PAGE_ALIGN((uintptr_t)buffer->data), (void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK), NULL); rb_erase(&buffer->rb_node, &proc->allocated_buffers); buffer->free = 1; if (!list_is_last(&buffer->entry, &proc->buffers)) { struct binder_buffer *next = list_entry(buffer->entry.next, struct binder_buffer, entry); if (next->free) { rb_erase(&next->rb_node, &proc->free_buffers); binder_delete_free_buffer(proc, next); } } if (proc->buffers.next != &buffer->entry) { struct binder_buffer *prev = list_entry(buffer->entry.prev, struct binder_buffer, entry); if (prev->free) { binder_delete_free_buffer(proc, buffer); rb_erase(&prev->rb_node, &proc->free_buffers); buffer = prev; } } binder_insert_free_buffer(proc, buffer); }
|
这里调用 binder_update_page_range 是第二个参数是传递 0 了,就表示是要释放物理内存映射,这个前面已经分析过了。然后从 allocated_buffers 中删掉这块 buffer,把 free 标志也设置一下。重点在后面:
判断这块是不是最后一块 buffer,这里其实就是向后查看后面那块 buffer 是不是也是 free 的(前面说 proc->buffers 是一个链表)。如果是的话,表示可以把这2块合并成一个更大的 buffer 块。这里插一句内存管理方面的常识,空闲的 buffer 块越大,下次申请成功概率就越大,所以要保证空闲 buffer 块尽量的大。如果 buffer 都是零零星星很小、数量很多的小块,那么下次申请很可能会失败,但是总体空间的大小却是够的,也就是我们常说的内存碎片。要尽可能的避免内存碎片,所以才需要有内存合并的处理。
那看看怎么合并的。要合并的话,先把后面那块从 free_buffers 中删掉,然后调用 binder_delete_buffer 去删除:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
| static void binder_delete_free_buffer(struct binder_proc *proc, struct binder_buffer *buffer) { struct binder_buffer *prev, *next = NULL; int free_page_end = 1; int free_page_start = 1; BUG_ON(proc->buffers.next == &buffer->entry); prev = list_entry(buffer->entry.prev, struct binder_buffer, entry); BUG_ON(!prev->free); if (buffer_end_page(prev) == buffer_start_page(buffer)) { free_page_start = 0; if (buffer_end_page(prev) == buffer_end_page(buffer)) free_page_end = 0; binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: merge free, buffer %p " "share page with %p\n", proc->pid, buffer, prev); } if (!list_is_last(&buffer->entry, &proc->buffers)) { next = list_entry(buffer->entry.next, struct binder_buffer, entry); if (buffer_start_page(next) == buffer_end_page(buffer)) { free_page_end = 0; if (buffer_start_page(next) == buffer_start_page(buffer)) free_page_start = 0; binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: merge free, buffer" " %p share page with %p\n", proc->pid, buffer, prev); } } list_del(&buffer->entry); if (free_page_start || free_page_end) { binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "binder: %d: merge free, buffer %p do " "not share page%s%s with with %p or %p\n", proc->pid, buffer, free_page_start ? "" : " end", free_page_end ? "" : " start", prev, next); binder_update_page_range(proc, 0, free_page_start ? buffer_start_page(buffer) : buffer_end_page(buffer), (free_page_end ? buffer_end_page(buffer) : buffer_start_page(buffer)) + PAGE_SIZE, NULL); } }
|
看到那个 BUG_ON(!prev->free) 感觉这个函数就是内存合并专用的,要调用这个释放 buffer 块,还必须前面那个块是 free 的,合并的时候就是这样(仔细看下前面,向前合并的时候,删除的是自己,所以前面那个也是 free 的)。然后后面的的判断是检测要释放的这块 buffer 所在的页面是不是别的 buffer 也在用。因为前面说了好几次了,一般一页是 4k, IPC 的参数经常只有几个、十几个字节而已,所以经常会一个页里面有好块 buffer。所以就向前(前一块)和向后(后一块)检测下自己的邻居是否和自己共用一个内存页:
1 2 3 4 5 6 7 8 9 10
| static void *buffer_start_page(struct binder_buffer *buffer) { return (void *)((uintptr_t)buffer & PAGE_MASK); } static void *buffer_end_page(struct binder_buffer *buffer) { return (void *)(((uintptr_t)(buffer + 1) - 1) & PAGE_MASK); }
|
检测方法和前面差不多就是拿地址进行页面内存对齐。看对齐后的地址是不是落在一起。然后设置2个标志。在最后判断,只要前后有一块 buffer 和自己共用一页就不释放这片地址的物理内存映射。否则就调用 binder_update_page_range 去把自己映射的这片物理内存释放掉。以前在大学里面听老师说内存对齐的问题是最麻烦的,后来敲了几年代码没啥感觉,现在深深感受到恶意啦,页面对齐、字节对齐 -_-||。
回到 binder_free_buf,向后合并是删掉后面那块(next),向前合并是删掉自己(buffer),拿 prev 重新当作自己。最后 binder_insert_free_buffer 把合并之后的 buffer 重新插入到 proc->free_buffers 中供下次申请的时候使用。
这个做法其实我和以前弄 MiniGUI 的一个 GAL 中的显存管理很类似,简单但是有效,可以来这里对比一下(那里还有图说明): STi7167 GAL 显存管理
总结
感觉 binder 下了不少功夫进行效率的优化:
- 通过将内核地址和用户地址映射到同一个物理地址以减少数据传递中 copy 的次数。
- 自己进行内存管理、快速查找(红黑树)、合并碎片。
- 线程池支持,提供高服务端并发的响应能力(后面再分析)。
- 以及等等 … …
另外 binder 还提供调用者和目的地的 pid 验证,对 IPC 的安全性也有提高。并且对上层提供友好的封装接口以及偷懒的代码自动生成工具(aidl),易用上也比传递 IPC 好。现在稍微能理解点 android 为什么要自己搞一套 IPC 的机制了。据说标准的 linux kernel 3.xx 好像加入 binder 了。